あけましておめでとうございます。アスタミューゼでデザイナーをしている@YojiShirakiです。
年末年始は皆さんいかがでしたでしょうか?
さて、今回は年始という区切りということで、当ブログのアクセス情報を紐解いて技術ブログで PV を稼ぐ記事のパターンを4つほどご紹介したいと思います。
目次
当ブログの現況
このブログは2016年6月にスタートして、次の6月で丸5年になります。投稿記事数は189本。あと3ヶ月もすれば200本を超える規模になります。毎週1本の投稿を目安にして、大きく停滞することもなく継続できています。
ブログの成果としては
- 採用に来る方が事前にブログを読んでいて良い印象を持っている
- 当社の技術についての事前知識を持っている
というのが大きいです。もちろん採用応募にも貢献してますが 数×効能=成果 と考えると、皆さんに「雰囲気が良さそうと感じる」とか「技術に積極的そう」という良い心象形成ができていることのほうが価値があるように感じます。
ブログのアクセス数ってどうなの?
さて、そんな当ブログ。「それなりにアクセスあるのでは?」と思われるかも知れませんが、多いかどうかはともかく、記事数に比例した積もり方をしているわけではありません。
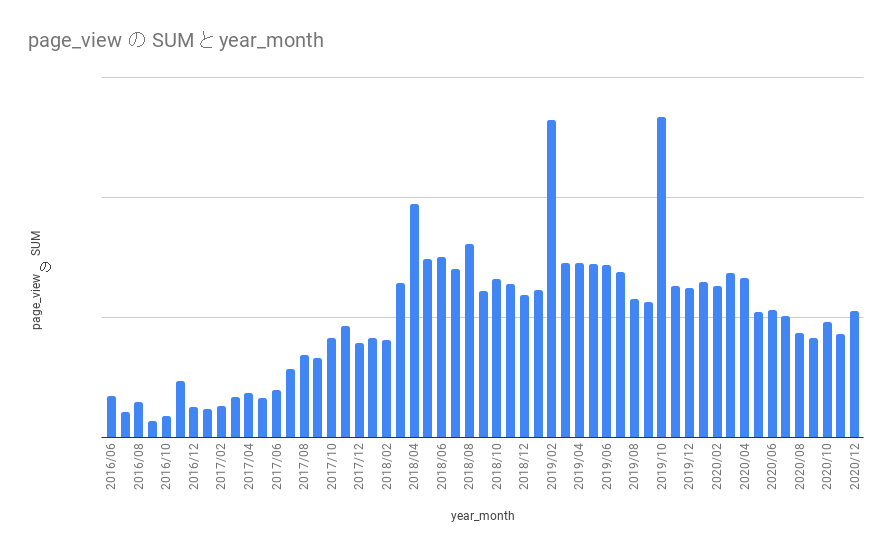
よく「コンテンツは資産だ」と言いますが記事には特質があり、それによって資産化する・しないが決まるため、その辺りの配合をマネージせねば全体としての資産性を向上させることができません。 今回はそういった課題意識も併せながら記事の特質を踏まえて PV を長く稼ぐ4つのパターンを紹介していきます。
技術ブログでPVを稼ぐ 4つの記事パターン
PVを稼ぐ記事 その1 「ハマれば強いニッチトップ記事」
PVを稼ぐ記事その1は「ニッチトップ」です。
まずは下記のグラフをご覧ください。これは2020年11月のアクセスについて、いつの投稿記事がPVを稼いでいるかを示したものです。
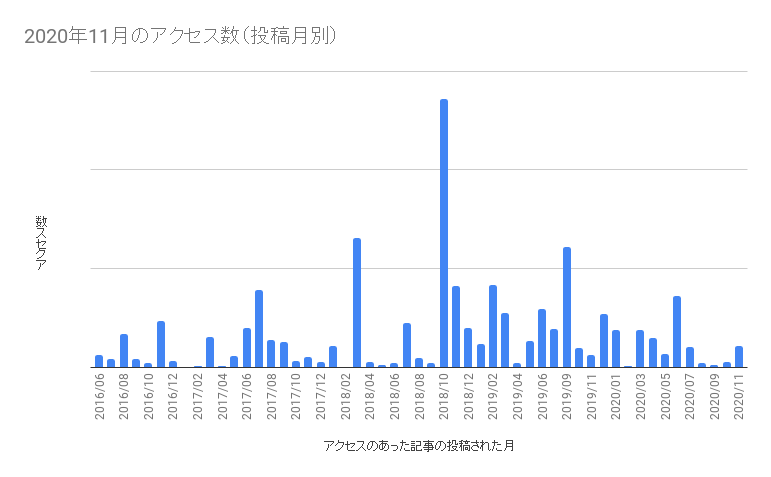
見ると、未だに2年前の2018年10月の記事がPVを稼いでいることがわかります。実はこれニッチトップ記事なんです。当該記事はこちら。
PXEブートについて非常に丁寧にかかれた記事で「pxeブート」で検索すると4番目に出てくる記事です。 競合となる記事も少なく、一方で対象読者もものすごい広いわけではないため、ニッチトップ的な位置を獲得できているといえます。この手の記事は一見すると ターゲットが狭くパッとしない記事かな と思ってしまいますが、そこが逆にニッチトップの感触といえます。たとえターゲットが少なくても競合が少なくても十分に PV を稼ぎます。またニッチトップ記事は競合が出にくいことも強みの一つです。
パフォーマンスの良いニッチトップ記事の要件は大きくは3点です。
- トピックがニッチで競合記事が少ないこと(「やってみた系」記事が少ないこと)
- 取り扱う技術トピックのレイヤーが低いものであること(インフラや、ミドルウェアなどは寿命が長いため資産になる)
- 最初から高度な内容を書かずに、その技術の呼び水的な内容であること
3番目が特に重要です。あまりに高度な内容にしすぎると対象読者をより一層狭めますから程よくエントリー向けにしておくのが吉です。これら3条件を満たし且つ 読みが当たれば ニッチトップ記事は息長くあなたのブログにPVを齎してくれます。 参考までに先ほどの PXEブート の記事のアクセス推移を掲載しておきます。
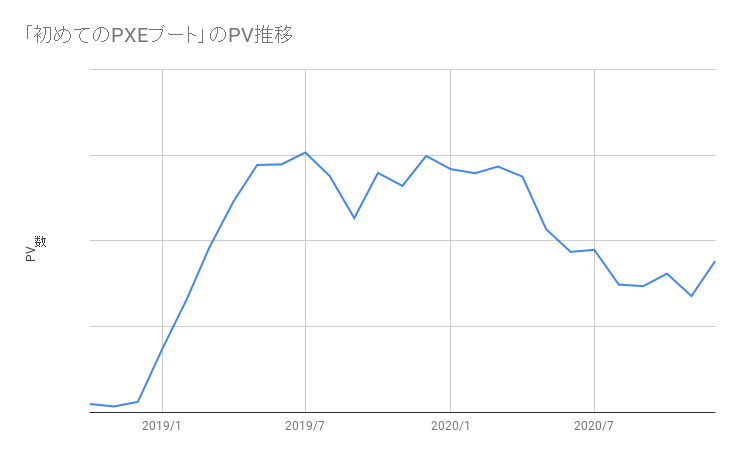
見るとわかるように投稿直後はそこまでアクセスがありません。しかし、月を追うごとにじわじわ伸びていっていますね。ニッチトップ系記事は対象読者数が多いわけではないので、最初から大きなアクセスは期待できませんが、徐々に記事の内容が評価され検索結果で上位に入り初めてパフォーマンスが安定します。
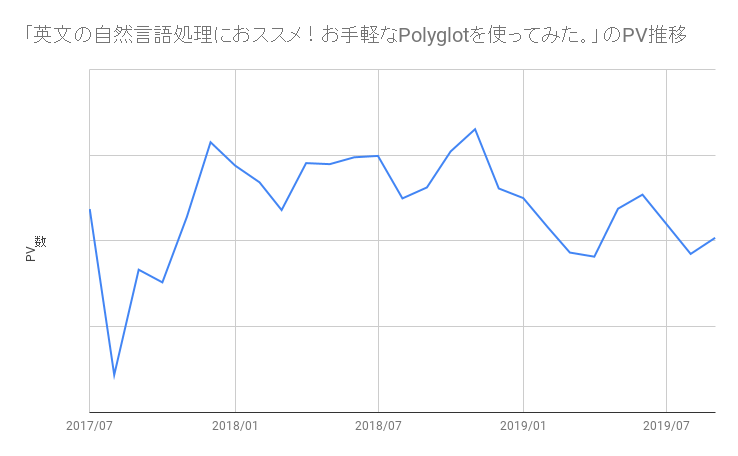
同じような傾向はこちらの記事にも見られます。
英文の自然言語処理におススメ!お手軽なPolyglotを使ってみた。 - astamuse Lab
こちらの記事も「polyglot python」で一位になっています。アクセスは初月にちょっと伸ばして、翌月に底を舐めその後徐々に安定してパフォーマンスを出しています。
ニッチトップ記事は書く前にある程度の調査が必要です。自身が持っている技術知識の中で先程の3条件に当てはまっているかどうか確認し、確信を得てから書くと良いでしょう。
PVを稼ぐ記事 その2 「持続性抜群のインフラ技術記事」
PVを稼ぐ記事のその2は 「インフラ技術記事」 です。
正確に言うと、インフラなど、劇的なパラダイム・シフトやバージョンアップが起きにくいレイヤーの技術記事 です。このパターンには 言語のリファレンス記事など(ex. https://note.nkmk.me/ )なども含みます 。当ブログの例で言えばこちら記事などがわかりやすい例です。
Linuxでユーザアカウントを無効化するエトセトラ - astamuse Lab
この手の記事は対象となる技術・ノウハウ自体の寿命が長いため底堅い PV を稼いでくれます。一事例ではありますが、当ブログの2020年11月のアクセスを見てみますと Linux 関連の記事が3本上位にランクインしています(★太字)。
| タイトル | 投稿月 | 月のPVに占める割合 |
|---|---|---|
| 初めてのPXEブート | 2018/10 | 8.03% |
| Pythonでも型を明記しよう | 2019/09 | 7.21% |
| ★Linuxでinodeが枯渇した場合にどうやって調査するか | 2018/03 | 7.11% |
| Vue.jsでAccordionを作ってみるく | 2018/10 | 5.92% |
| 仕事用ディスプレイを 4K で作業してみました | 2019/02 | 4.75% |
| 英文の自然言語処理におススメ!お手軽なPolyglotを使ってみた。 | 2017/07 | 4.62% |
| ★/etc/hosts で同じホスト名に違うIPアドレスを設定したらどうなるか | 2018/11 | 4.34% |
| ★Linuxでユーザアカウントを無効化するエトセトラ | 2019/03 | 3.08% |
| デザイン採用担当はポートフォリオで何を見ているか、何が見えているか? | 2016/11 | 2.46% |
| 特異値分解と行列の低ランク近似 | 2017/06 | 2.26% |
| Python が Cloud Functionsで使えるようになったので試してみました | 2018/10 | 2.07% |
いずれも一年以上前の投稿にも関わらず安定的に PV を叩いています。こちらも参考までにPV数をグラフにすると下図のような推移です。
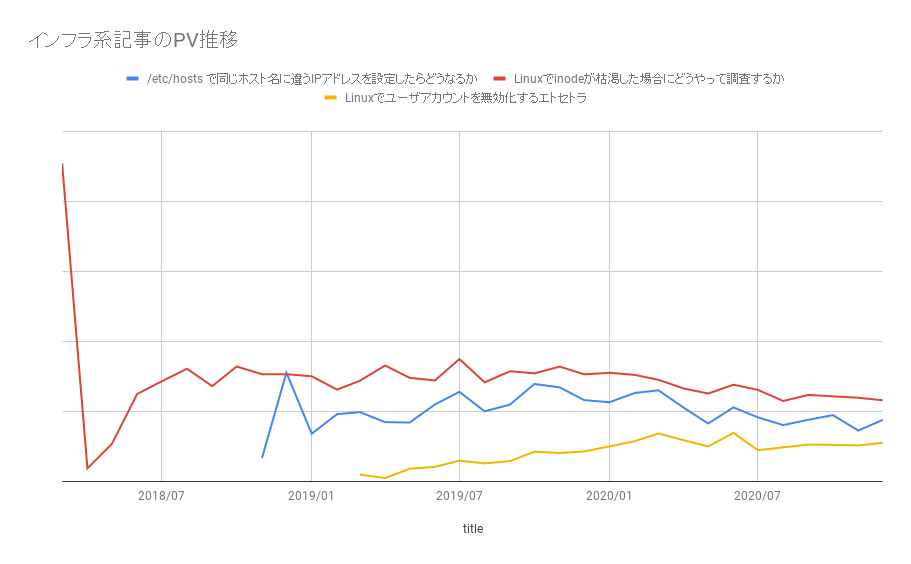
長く継続的にアクセスを稼いでますね。(@namikawa)曰く「 Ubuntu の OS 調べる記事が結構なPVを稼いでくれる 」とのことで
cat /etc/os-release って打つだけの記事といえどもインフラの記事というのは侮れないのが実際のところです。ブログを伸ばすならこうした底堅い隙間ネタを見つける能力が大事なのでしょう。ただ一方で会社ブログで cat /etc/os-release の記事を書くかどうかはブログの方針にもよりますから留意が必要です。
PVを稼ぐ記事 その3 「数理系・統計処理系記事(但し平易でコード付き)」
PVを稼ぐ記事のその3は 「数理系・統計処理系記事(但し平易でコード付き)」 です。ちょっと分かりにくいですが例えばこういう記事です。
- 特異値分解と行列の低ランク近似 - astamuse Lab
- Pythonでコレスポンデンス分析をやってみた - astamuse Lab
- お手軽に英文文書にメタ情報を!!Pythonでgensimを使ったLDAに挑戦してみた。 - astamuse Lab
数理モデルを用いる実装というのは慣れてない方には敷居が高いため入門記事ニーズはそれなりあります。そういう方たちにとってこの手の記事は
- 数理モデルの理解を助けてくれる
- しかもその実装の仕方を教えてくれる
という点で非常に重宝されます(それがいいかどうかは置いておきますが)。先の紹介した記事だと特異値分解はちょっと専門的で、コレスポンデンス分析はロジックの言及がちょっと薄い感もありますが、この感触でも PV は継続的に上げてくれます。 誰しも TF-IDF を実装しようとしたときに 丁度いい感じにわかりやすくまとまった、しかも実装コードも書いてくれている投稿 を探した経験はあるかと思いますが、そんなニーズにフィットするような記事が良いのかと思います。
PVを稼ぐ記事 その4 「その他ライフハック系・ノウハウ記事」
最後にご紹介するPVを稼ぐ記事のその3は「その他ライフハック系・ノウハウ記事」です。
まぁ、これは catch-all 的な分類ではありますが、このような記事です。
いずれも開発・デザインの傍流の記事ですが非常にPVが高い記事です。 この手の記事のアクセスパターンは2つに大別されます。
- 最初にバズって先3~5年分のPVを稼ぎに行くケース
- 持続的にPVを稼ぎに行くケース
先の 4Kディスプレイの記事は公開一週間で万単位のPVを叩きまして今も持続的にPVがあります。ご存知の通りライフハック系はバズるポテンシャルが高く、タイトル次第では驚くくらいのパフォーマンスを発揮します。しかもそれが瞬間風速でとどまらず初月過ぎても数字を出し続けるのです。
一方、ノウハウ記事も年間で1万程度の PV を数年にわたって出しますので侮れません。勿論そういう記事は踏み込んだノウハウ記事に限られますが、ブログの他の記事との相性が良ければ十分資産になり得るものです。また、後ほど紹介しますが、うまくリバイブできればより長い寿命を獲得できるでしょう。
番外編:その他の記事パターン
せっかくなので当ブログで掲載されている他のパターンもご紹介します。
思索系記事
思索系記事は寿命が1年程度という感触です。最初にバズると長寿になりますがそれでも2年くらいです。
思索系記事は作成コストが高いため皆さん投稿したがりません。ただ、そういった記事だからこそ、また一人の人間が仕事を通して培った思考が蓄積された記事だからこそ、共感 や 尊敬 を集めることができるのも特徴です。 そう考えると、この手の記事をそれなりに広げるならば、予め業界のオピニオンリーダーに retweet されたり シェアされるように仕込んでおく、というような戦術は良い戦術と言えます。
トレンド技術系記事
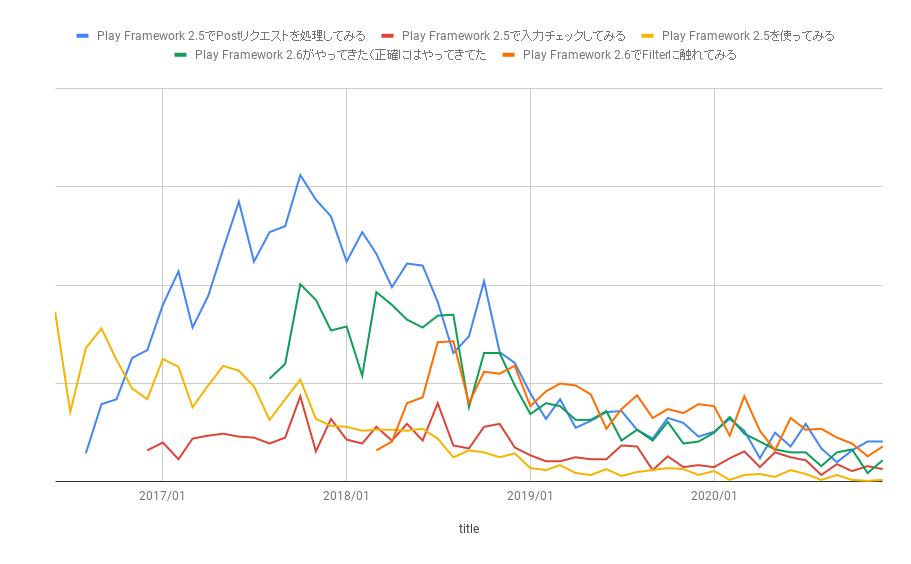
トレンド技術記事は対象となる技術にもよりますが大体2年程度の寿命という印象です。当ブログには PlayFramework2.5 ~ 2.6 の記事がありますが PV 推移で見ると2年程度でアクセスが落ちています。
- Play Framework 2.5を使ってみる - astamuse Lab
- Play Framework 2.5でPostリクエストを処理してみる - astamuse Lab
- Play Framework 2.5で入力チェックしてみる - astamuse Lab
- Play Framework 2.6がやってきた(正確にはやってきてた - astamuse Lab
- Play Framework 2.6でFilterに触れてみる - astamuse Lab
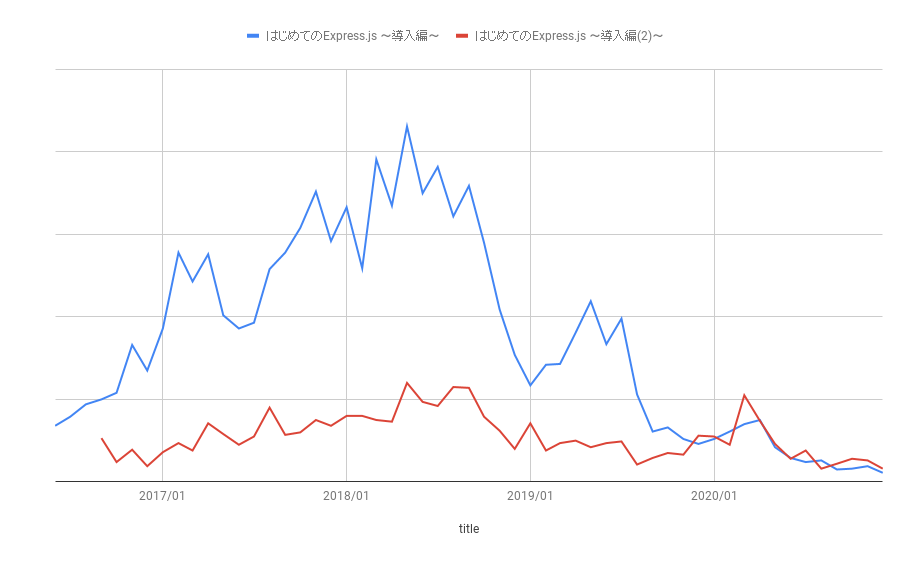
Express.js の記事も概ねそれくらいの寿命です。フロントエンドなのでもう少し短いかと思いましたがそうでもないですね(フロントエンドの技術が落ち着いてきたのでしょう)。
技術ブログなので、こういった記事は勿論あって然るべきですがトレンド技術記事の寿命が2年ということは頭に入れておいて良いかと思います。
タイトルと SEO は超重要
と、色々申しましたが、そもそも論として記事で PV を稼ぐには タイトル が超重要であることはここで強く申し上げておきます。バズるようにするのか長く普遍的に利用される記事にするのか、こういった 記事の狙い によってワーディングは変わるものの、いずれせよ最低限 伝わるタイトル がなければ SNS でも Google の検索結果でもクリックを誘引することはないでしょう。ぜひ一度、自身の書いた記事のタイトルを見直して下記の3つを考えてみてください。
- タイトルが記事の内容を表しているか
- タイトルが興味を惹く様になっているか(これが凄まじく奥深いですが)
- どういう検索ワードで検索してほしいかを考え、そのワードの検索結果にこのタイトルがあったらクリックするか
もし見直してイマイチいけてないタイトルだったら修正しておきましょう。
また、改めて記事の内容を確認して狙っている読者とキーワードのフィッティング、密度などを確認されると良いと思います。
最後に
最後にこの分析データを Google Analytics API から取得するスクリプトを置いておきます。かなりざっと書いてしまったのでロギングとか例外処理はありませんが、参考にはなるかと思います。
# -*- coding:utf-8 -*- from apiclient.discovery import build from oauth2client.service_account import ServiceAccountCredentials import os import re import time import datetime import csv from dateutil.relativedelta import relativedelta SCOPES = ['https://www.googleapis.com/auth/analytics.readonly'] KEY_FILE_PATH = os.path.dirname(os.path.abspath(__file__)) + '/secret_key.json' OUTPUT_FILE_PATH = os.path.dirname(os.path.abspath(__file__)) + '/access_data.csv' VIEW_ID = 'xxxxxxxxx' def initialize_analyticsreporting(): """Initializes an Analytics Reporting API V4 service object. Returns: An authorized Analytics Reporting API V4 service object. """ credentials = ServiceAccountCredentials.from_json_keyfile_name( KEY_FILE_PATH, SCOPES) # Build the service object. analytics = build('analyticsreporting', 'v4', credentials=credentials) return analytics def fetch_blog_post_url(analytics) -> list : """ GAで計測されているページのURLとタイトルを返します """ start_date = "2015-01-01" end_date = "today" result = analytics.reports().batchGet( body={ 'reportRequests': [ { 'viewId' : VIEW_ID, 'dateRanges' : [{'startDate': start_date, 'endDate': end_date}], 'metrics' : [{'expression' : 'ga:pageviews'}], 'dimensions' : [{'name' : 'ga:pagePath'}, {'name' : 'ga:pageTitle'}], 'orderBys' : [{'fieldName' : 'ga:pageviews', 'sortOrder' : 'DESCENDING'}] } ] } ).execute() posts_data = [] for report in result.get('reports', []): for row in report.get('data', {}).get('rows', []): path = row['dimensions'][0] title = row['dimensions'][1] if re.match(r"^/entry/", path) and 'Entry is not found' not in title: posts_data.append({ 'path' : path , 'title' : title }) return posts_data def fetch_post_access_data(path, analytics) -> dict: """ 対象URLの週次のアクセス数を取得します """ start_date = "YYYY-MM-DD" # 適宜書き換えてください(計測したい最初の月) end_date = "today" result = analytics.reports().batchGet( body={ 'reportRequests': [ { 'viewId' : VIEW_ID, 'dateRanges' : [{'startDate': start_date, 'endDate': end_date}], 'metrics' : [{'expression' : 'ga:pageviews'}], 'dimensions' : [{'name' : 'ga:pagePath' }, {'name' : 'ga:yearMonth'}], "dimensionFilterClauses" : [{ "filters" : [ { "dimensionName" : 'ga:pagePath', "operator" : 'REGEXP', "expressions" : ["^" + path] } ] }], 'orderBys' : [{'fieldName' : 'ga:yearMonth', 'sortOrder' : 'ASCENDING'}] } ] } ).execute() access_data = {} for report in result.get('reports', []): rows = report.get('data', {}).get('rows', []) if len(rows) == 0 : continue access_month_dt = datetime.datetime.strptime(rows[0]['dimensions'][1], '%Y%m') today = datetime.datetime.now() # アクセスがない月は参照すべきデータがAPIのレスポンス内にないので予めデータの受け皿を作っておく index = 0 while access_month_dt < today: access_data[access_month_dt.strftime('%Y/%m')] = { 'index' : index, 'page_view' : 0 } access_month_dt += relativedelta(months=1) index += 1 # 改めてデータを走査 for row in rows: year_month_dt = datetime.datetime.strptime(row['dimensions'][1], '%Y%m') year_month = year_month_dt.strftime('%Y/%m') page_view = int(row['metrics'][0]['values'][0]) access_data[year_month]['page_view'] += page_view return access_data def main(): ofp = open(OUTPUT_FILE, 'w', encoding='utf-8', newline="") writer = csv.writer(ofp, delimiter=",", quoting=csv.QUOTE_ALL) analytics = initialize_analyticsreporting() posts_data = fetch_blog_post_url(analytics) data_length = len(posts_data) for i, post_data in enumerate(posts_data): time.sleep(3) path = post_data['path'] title = post_data['title'] print("{0}/{1} {2}".format(i, data_length, path)) access_data = fetch_post_access_data(post_data['path'], analytics) for year_month, data in access_data.items(): writer.writerow([data['index'], path, title, year_month, data['page_view']]) if __name__ == '__main__': main()
では、本日も最後までお読みいただきありがとうございました。
例によって当社では一緒にサービス開発してくれるエンジニア・デザイナー・ディレクターを募集しております。カジュアル面談も随時行っておりますので、「ちょっと話聞きたい」という方は、このブログのサイドバー下にあるアドレスか@YojiShirakiにDMいただければと思います。採用サイトもありますので下の水色のバナーから是非どうぞ!
(@YojiShirakiの過去記事)
- デザイン採用担当はポートフォリオで何を見ているか、何が見えているか?
- 広告費用を自動取得し100時間分の作業をなくす話
- プロジェクトにBIツール「metabase」を導入したらいい感じになった話。
- 英文の自然言語処理におススメ!お手軽なPolyglotを使ってみた。
- お手軽に英文文書にメタ情報を!!Pythonでgensimを使ったLDAに挑戦してみた。
- オフィス移転したので移転ポイント・反省をまとめてみた
- Python が Cloud Functionsで使えるようになったので試してみました
- デザイナーが「デザイン経営」宣言を読んでみた
- デザイナーもデブサミに行った方がいい理由をざっくりまとめてみた
- デザイナーが「言葉」についてちょっと真面目に考えてみた
- デザイナーだけどデブサミいってきたよ #devsumi