はじめまして。データチームのKimy(@yuu_kimy)です。
日々、各種データの整備に関わる開発を行っています。
早いもので、アスタミューゼにジョインしてから、1年が過ぎました。
ジョインしてから、グラント(研究助成)や特許データの整備開発、各種案件対応を行ってきましたが、最近では、特許の概念や用語の勉強の日々です。
だいぶ慣れてきたかなと感じていますが、やっぱり、難しいですね..
さて、案件対応では、蓄積されたデータを活用して、各種データの加工・集計等を行っていますが、様々なデータを利用することで、データのインプット・アウトプットの流れが分かり辛くなってくることがあります。
利用するテーブルが数個であれば、そのデータを処理するソースコードを見れば、パッと流れが掴めますが、数多くのテーブルを利用して、集計して、集計した結果を別に処理をした結果とジョインして、更に、フィルターをかけて..etc となってくると、処理が複雑となり、大まかな流れが掴み辛くなってきます。
データマネジメント領域で言う「データリネージ」(どのデータを利用して、どう生成されているかが明らかになっていること)ができると何かと便利そうなので、簡易的なデータリネージにトライしてみたいと思います。
今回は、SQLに対するデータリネージをやってみます。
(SQLであれば、何でも大丈夫だと思います。)
データリネージとは?
前述の通り、「どのデータを使って、どういう風に生成しているか」といったデータの流れが整理・可視化されることを指します。また、データの処理における変換も対象となります。
データリネージにより、データガバナンスにおける色々な検証を可能にするかと思いますが、それだけで話が多岐に渡りそうなので、詳細は割愛させて頂きます。
Pythonモジュールの「sqllineage」について
Pythonのモジュールに、sqllineage なるツールを聞きつけたので、試しに使ってみたいと思います。
このツールは、SQLを解析して、ソーステーブルやターゲットテーブルの情報を教えてくれる便利なものです。(裏側では、sqlparseというSQLパーサが利用されているようです。)
早速、使ってみる
インストールは、非常に簡単です。以下を実行するだけです。
pip install sqllineage
インストール後は、ドキュメントにあるように、以下のようにコマンドを実行すれば、SQLの解析結果を表示してくれます。
sqllineage -e "insert into table_foo
select * from table_bar union select * from table_baz"
結果は、以下のように表示されます。
Statements(#): 1
Source Tables:
<default>.table_bar
<default>.table_baz
Target Tables:
<default>.table_foo
SQLに書かれている通り、ソーステーブルの"table_bar" と "table_baz"、ターゲットテーブルの"table_foo"が表示されています。
SQLを解析してみる
それでは、SQLを解析してみます。コマンドに、SQLの全てを書くのは面倒なので、クエリファイルに保存してから、先ほどと同様に、コマンドを実行します。
# 検証用SQL: target_sql_1.sqlとして保存 # 注意: 以下のSQLは、あくまで、今回のサンプル用に用意したものです。(以下同様) CREATE TABLE output.final_result_table AS WITH intermediate_table AS ( SELECT input_table_1.original_col_1, input_table_2.original_col_2, LEFT(input_table_3.original_col_3, 4) AS converted_col_3 FROM input.input_table_1 AS input_table_1 INNER JOIN input.input_table_2 AS input_table_2 ON input_table_1.dummy_common_col_1 = input_table_2.dummy_common_col_1 AND input_table_2.dummiy_flag = '1' INNER JOIN input.input_table_3 AS input_table_3 ON input_table_2.dummy_common_col_2 = input_table_3.dummy_common_col_2 ) SELECT input_table_5.original_col_5, input_table_6.original_col_6, input_table_7.original_col_7, ROUND(input_table_8.original_col_8 / input_table_9.original_col_9) AS round_result_1, intermediate_table.original_col_1, intermediate_table.original_col_2, intermediate_table.converted_col_3 FROM input.input_table_5 AS input_table_5 LEFT JOIN input.input_table_6 AS input_table_6 ON input_table_5.dummy_common_col_5 = input_table_6.dummy_common_col_5 LEFT JOIN input.input_table_7 AS input_table_7 ON input_table_6.dummy_common_col_6 = input_table_7.dummy_common_col_6 LEFT JOIN input.input_table_8 AS input_table_8 ON input_table_7.dummy_common_col_7 = input_table_8.dummy_common_col_7 LEFT JOIN input.input_table_9 AS input_table_9 ON input_table_8.dummy_common_col_8 = input_table_9.dummy_common_col_8 LEFT JOIN intermediate_table ON input_table_9.dummy_common_col_9 = intermediate_table.dummy_common_col_9
上記のSQLを解析してみます。クエリファイルを指定する場合は、-f のオプションを指定します。
sqllineage -f target_sql_1.sql
結果は以下の通りです。
Statements(#): 1
Source Tables:
input.input_table_1
input.input_table_2
input.input_table_3
input.input_table_5
input.input_table_6
input.input_table_7
input.input_table_8
input.input_table_9
Target Tables:
output.final_result_table
WITH句で利用したテーブルのinput_table_1〜3も、きちんと、ソーステーブルとして表示されているようです。
更に、詳細な情報が欲しい場合は、-v オプションも指定して、実行します。(-v -fの順番で指定する必要があるようです。)
次は、以下のSQLで解析を実行してみます。
## 検証用SQL: target_sql_2.sqlとして保存 INSERT INTO output.final_result_table_2 SELECT input_table_1.original_col_1, converted_table.common_col_2_1, converted_table.converted_rank, input_table_3.original_col_3 FROM input.input_table_1 AS input_table_1 INNER JOIN ( SELECT DISTINCT common_col_2_1, common_col_2_2, RANK() OVER ( PARTITION BY common_col_2_1 ORDER BY common_col_2_2 ) AS converted_rank FROM input.input_table_2 ) AS converted_table ON input_table_1.common_col_1 = converted_table.common_col_1 INNER JOIN input.input_table_3 AS input_table_3 ON input_table_1.common_col_2 = input_table_3.common_col_2 WHERE input_table_3.dummy_flag = '1' AND input_table_3.dummy_date <= '2021-09-21'
以下のように実行します。
sqllineage -v -f target_sql_2.sql
結果は、以下の通りです。
Statement #1: INSERT INTO output.final_result_table_2SELECT inp...
table read: [Table: input.input_table_1, Table: input.input_table_2, Table: input.input_table_3]
table write: [Table: output.final_result_table_2]
table rename: []
table drop: []
table intermediate: []
==========
Summary:
Statements(#): 1
Source Tables:
input.input_table_1
input.input_table_2
input.input_table_3
Target Tables:
output.final_result_table_2
サブクエリの中で呼び出している input_table_2 も、きちんと、ソーステーブルに含まれているようです。
-v オプションを付けることで、SQLのステートメントごとのREAD/WRITE等を表示してくれるようですね。
更には、SQLの解析結果を可視化することも可能です。
# -gオプションをつけて実行する sqllineage -g -f target_sql/target_sql_5.sql
実行すると、リンクが表示されますので、ブラウザからアクセスすると、以下のような描画が表示されます。
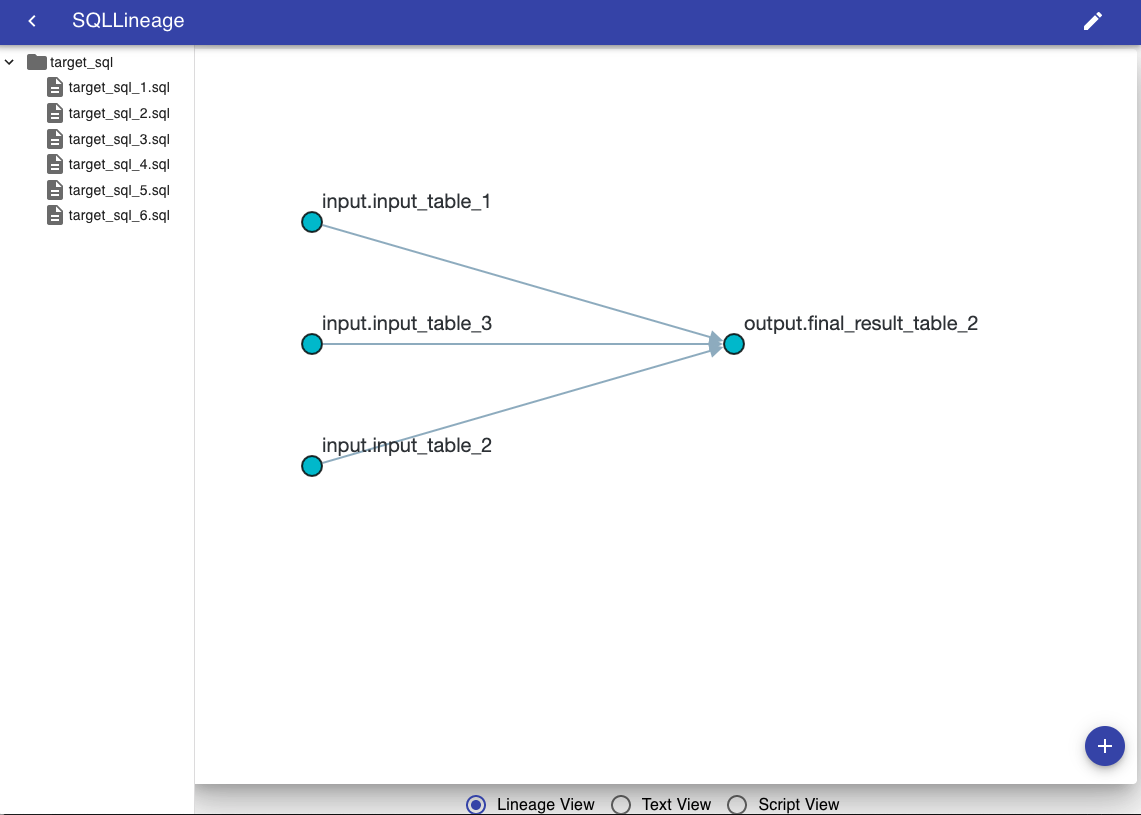
描画されたテーブルのノードにカーソルを当てると、ハイライトしてくれるようですね。
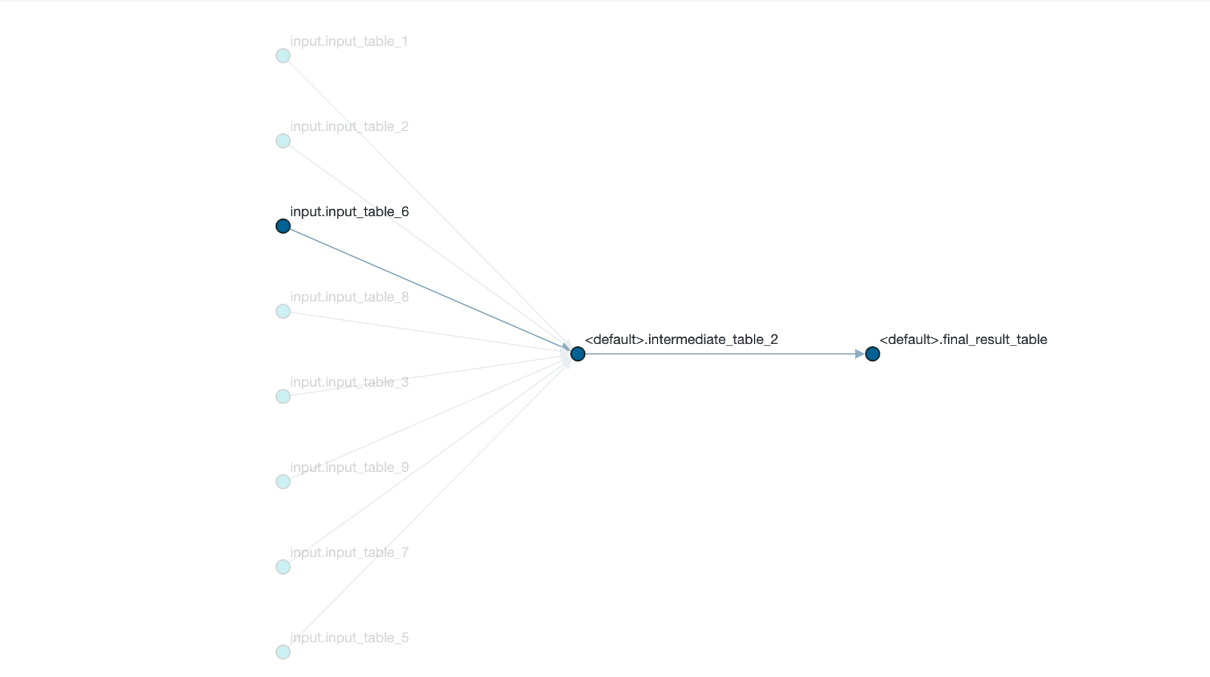
SQLのテーブルのインプットとアウトプットの流れが、パッと見て、分かる状態になりました。
まとめ
sqllineageを利用することで、SQLの流れを容易に掴むことができました。今回のサンプルでは、シンプルなSQLでしたが、更に、複雑なSQLだと、その威力を発揮してくれそうです。
ただ、あくまで、テーブルのインプットとアウトプットの流れを掴むことがメインのため、カラムレベルまで踏み込んだデータリネージではないようです。
また、注意ですが、sqllineage (その裏側で動いているsqlparse)は、SQL自体の妥当性をチェックしているわけではないので、本来は、エラーが発生するようなSQLでも、リネージが表示されてしまいます。その場合、想定した解析結果にならないケースもあり得るため、注意が必要なようです。
アスタミューゼでは、エンジニア・デザイナーを募集中です。ご興味のある方は、弊社の採用サイトからご応募頂けたらと思います。
ご応募をお待ちしておりますm( )m