
こんにちは。白木(@YojiShiraki)です。デザイナーです。
前回はpolyglotを用いて英文から名詞を抽出する処理を行いました。今回は、その延長でLDAという手法にチャレンジしたいと思います。
背景
当社ではぼちぼち大量の自然文章データを取り扱っています。通常、これらのデータを読み解いてクライアントへの提案に繋げているのですが、概観を把握する場合は、膨大なデータを一つ一つ丁寧に読んでいる余裕などありません。
そうなると、できる限りメタ情報を付与して、対象データの中身を読まずにだいたい把握するニーズが高くなりますが、残念ながら最初からデータに豊かなメタ情報が付与されているケースは稀であり、あってもカテゴリが一つ与えられているくらいです。
そこで自分たちでメタ情報を付与できないか、ということでLDAをやってみたという流れです。
LDAとは?
ざっくり言うと、対象となる文書がどういったトピックによって構成されているかを推定する方法です。潜在的ディレクリ配分法と言われます。数学的な解説は他サイトに譲りまして、ここでは直感的にLDAがどういったものか解説します。
まず、ある文書があったときに、その文書のトピックとは何か、ということです。
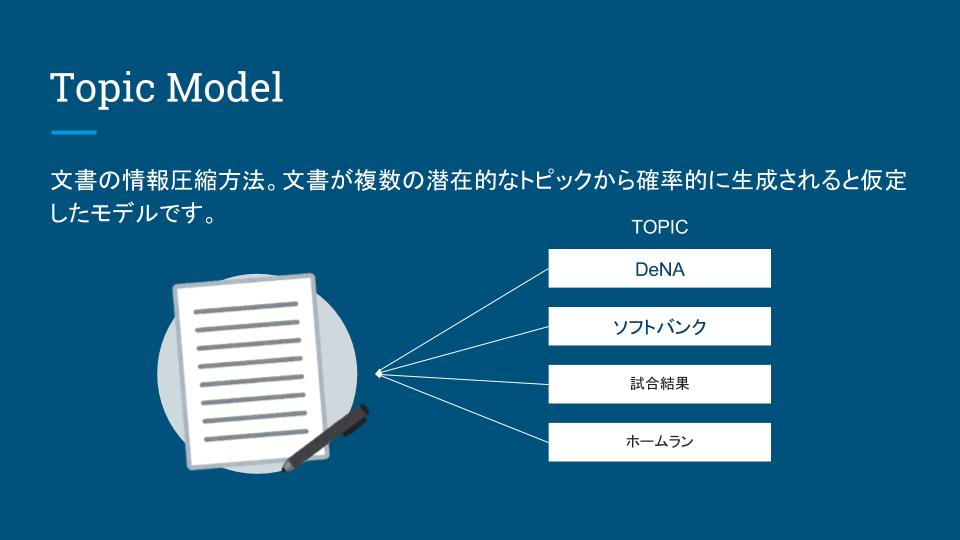
例えばある野球ニュースがあったしましょう、この時、その文書(ニュース)がクライマックスシリーズのニュースであればトピックは「DeNA」「ソフトバンク」「試合結果」「ホームラン」といったところでしょうか。こういった情報が把握できればニュースを全部読まなくてもだいたい何の話かわかりますよね。
注意点
「なんだ楽勝じゃん」と思われるかもしれませんが注意点が二つあります。
- トピックは母集団となる文書群から抽出される
- トピックは明確的には抽出できない
どういうこと?と思われるでしょう。以下に簡単に説明いたします。
1.トピックは母集団となる文書群から抽出される
文書の成分として推定されるトピックは対象となる文書群から抽出されます。 例えば以下の二つのケースを考えてみます。
- 日本のすべてのニュース(文書群)を対象としてトピックを推定した場合
- スポーツニュース(文書群)を対象としてトピック推定をした場合
1の場合、おそらく上がってくるトピックは「経済」「政治」「芸能」「スポーツ」などで、2の場合は「野球」「サッカー」「バスケット」「ラグビー」などでしょう。
1よりも2の方がスポーツに関して偏った文書群であり、自然と単語の出現頻度もより具体的な単語が支配的になるためです。
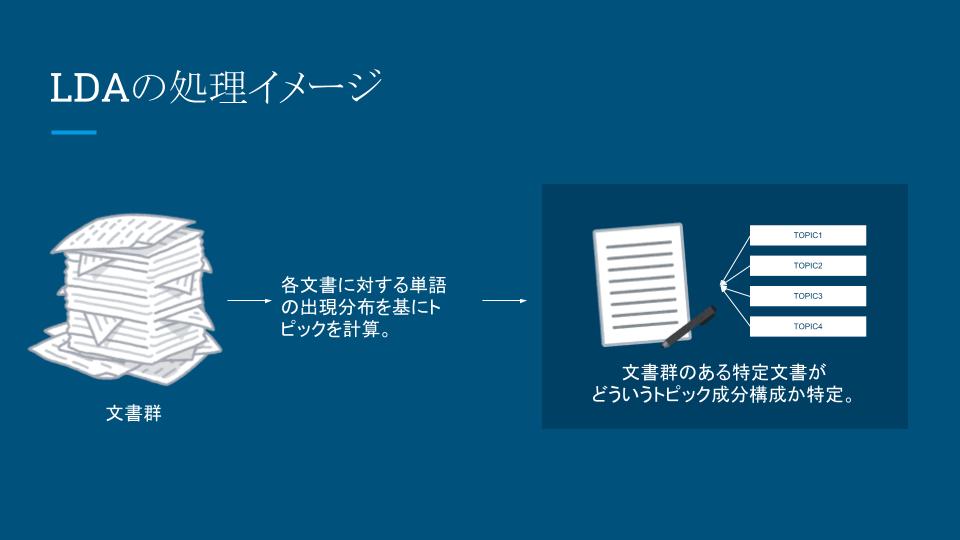
2.トピックは明確的には抽出できない
ここまでで便宜上ではあったにせよトピックは「経済」「政治」「野球」「サッカー」など、明確に与えられるように書きました。しかし実際はトピックも単語の成分として与えられます(OMG)。
イメージとしては以下のようなものです。

つまり処理手順はこういうイメージです
- 文書群から
- トピック成分を抽出し
- トピックを定義する
- そのうえで個別の文書を分析にかけ
- その文書のトピックの構成比率を明らかにする
実践
ということであとはコードでも書いていきましょう。前回ご紹介したPolyglotを利用してますので、まだご存じない方はこちら)をご覧ください。
なお、以下のコードは説明しやすいよう便宜的なデータセットで用意しています。実際はちゃんとDBを使ってデータの管理を行なっております。また本筋に関連の薄い処理は割愛しております。あらかじめご了承ください。
1. 名詞の抽出
polyglot)を利用します。
from polyglot.text import Text from polyglot.detect import Detector # 文書群(実際にはこういった文書が100万以上あるイメージです) documents = [ { 'desc' : 'A beach safe for all those who want a carefree beach holiday. The HBT BELSAFER the HBT brings a mobile vault on the market, which offers a premium value protection with smart additional features.' }, { 'desc' : 'The south curve must stay! The SOUTH CURVE is THE place of active FCC fans. Here come for generations the blue-yellow-white trailer together, showing brilliant choreography, are creative and unmistakable behind their team.' }, { 'desc' : 'Darling4me - Video Dating and dating service on the smartphone. Find your soul mate on the smartphone with just one click on your smartphone. Darling4me is the first truly Video Dating app for your smartphone (Iphone, Ipad and Android). Darling4me dating service does not require lengthy questionnaires and extensive information from you to find your soul mate. They are tired of seeing it on various dating sites on the Internet images of singles that look quite different in reality? They also do not believe that you will find his true love with a questionnaire? Then try just the new Video Dating Darling4me! It has never been easier to find love. Get your partner suggestions from your environment and see with just one click on your smartphone, the videos of the singles that could be suitable for you. Live and real!' } ] for doc in documents: desc = doc['desc'] text = Text(desc) nouns = [] for tag in text.pos_tags: word = tag[0] word_class = tag[1] if word_class != 'NOUN': continue if len(word) < 3: continue nouns.append(word.lower()) doc['nouns'] = nouns print(nouns)
こんな名詞データが取れます。実際には名詞データを格納する際にクレンジングなどを行う必要があります。今回はサンプルとして2文字以下の名詞は含めない処理を書いてあります。
['beach', 'beach', 'holiday', 'vault', 'market', 'premium', 'value', 'protection', 'features'] ['south', 'curve', 'curve', 'place', 'fans', 'generations', 'blue', 'trailer', 'choreography', 'team'] ['video', 'dating', 'service', 'smartphone', 'soul', 'mate', 'smartphone', 'smartphone', 'video', 'dating', 'app', 'smartphone', 'iphone', 'ipad', 'service', 'questionnaires', 'information', 'soul', 'mate', 'dating', 'sites', 'images', 'singles', 'reality', 'love', 'questionnaire', 'video', 'dating', 'love', 'partner', 'suggestions', 'environment', 'smartphone', 'videos', 'singles', 'live']
2.辞書の作成
先ほど抽出した名詞の配列から、単語と出願回数がペアになったデータを整備します。このタイミングで出現頻度の著しく高い単語や低い単語をフィルタリングしておきます。
import gensim from gensim import corpora, models, similarities words = [x['nouns'] for x in documents] dictionary = corpora.Dictionary(words) # 出現頻度の100回以下の単語は除外 # 5割の文書に出現している単語は除外 dictionary.filter_extremes(no_below=100, no_above=0.5) # 必要であれば辞書データを保存しておいてください。 dictionary.save_as_text('dict.txt') # 保存した辞書のロード dictionary = corpora.Dictionary.load_from_text('dict.txt')
辞書の中はこのような形です。
99416 142 ability 1285 269 access 1190 112 accident 1059 175 account 1100 250 action 1077 164 activities 2936 48 activity 1239 369 addition 3438 61 adults 1203 208 advance 1527 85 age 2557 323 amount 4965 244 animals 1380 260 anyone 2604 94 anything 3794 362 area 3266 147 areas 1832 66 art 2847
左からID, 単語, 出現回数となっています。
3.辞書と単語配列データからコーパスデータを作成
ここでは単語とその出現回数をセットにしたデータ(BoW)のまとまりをコーパスと呼びます。
corpus = [] for word in words: bow = dictionary.doc2bow(word) corpus.append(bow) print(len(corpus)) for c in corpus: print(c[0:5])
出力内容はこちら。
99416 [(226, 1), (348, 1)] [(16, 1), (386, 1)] [(22, 2), (73, 3), (107, 1), (213, 1), (256, 1)] [(16, 1), (32, 1), (38, 1), (51, 2), (53, 5)] [(13, 2), (27, 13), (44, 1), (50, 1), (53, 2)] [(112, 1), (227, 1), (256, 2), (358, 1), (367, 1)] [(120, 1), (130, 1), (222, 1), (404, 1)] [(130, 2), (205, 1), (234, 1), (275, 1), (349, 1)]
先ほどの辞書のIDの単語が各ドキュメントで何回出現しているのかが見て取れます。
4.トピックの抽出
さて全体での単語の出現頻度や、個別文書での単語の出現頻度のデータが整備できました。これによって出現確率が計算できるようになります。コード上でもいよいよトピックの抽出を行います。
topic_N = 5 # トピックの数(これは恣意的に設定できる。対象文書群が大きいなら数字は10にするなど) lda = gensim.models.ldamodel.LdaModel( corpus = corpus , num_topics = topic_N , id2word = dictionary ) # モデルを保存する lda.save('cf_lda.model') # 見やすく出力 for i in range(topic_N): print("\n") print("="*80) print("TOPIC {0}\n".format(i)) topic = lda.show_topic(i) for t in topic: print("{0:20s}{1}".format(t[0], t[1]))
出力はこんな感じです。
================================================================================ TOPIC 0 children 0.04091190129015311 community 0.03130555261697799 people 0.029479935059319066 school 0.02772734591535905 trip 0.024166451030072957 families 0.02161773848009083 food 0.021610873859255263 students 0.01979379324892966 funds 0.017129066919807687 donations 0.016645475281216793 ================================================================================ TOPIC 1 family 0.05142340959037838 time 0.02913106744366217 life 0.027162997294828555 years 0.024956546073125124 home 0.01966655399836955 year 0.018690935949895755 bills 0.018176062282802562 cancer 0.017468175859926792 kids 0.016755068548548788 surgery 0.016417772028110674 ================================================================================ TOPIC 2 cause 0.3400466352795431 progress 0.3288091973047845 supporter 0.326162187172668 name 0.002616388814580179 list 0.0007183396591630143 style 0.0001032523653516189 size 5.034349340074679e-05 time 1.8874650176037916e-05 business 1.802981647432903e-05 text 1.8023864292905654e-05 ================================================================================ TOPIC 3 name 0.04493116909991208 dream 0.03237160912917436 team 0.026269755943711323 music 0.024893502207153875 time 0.01889772053109854 equipment 0.018581267347826023 http 0.017372070771627068 support 0.017230217254967435 girls 0.016372972121079955 year 0.016264355823729516 ================================================================================ TOPIC 4 people 0.03610631244471521 business 0.0258750156278881 world 0.023791209653958246 life 0.02243440793115274 time 0.018039148524328114 way 0.015300038103529194 project 0.014480208478364773 years 0.01395798245176747 campaign 0.012818022865819834 work 0.011415802285745767
面白いですね。ところどころでnameやhttpなどのノイズがあるので、これは調整が必要そうです。ストップワード作ってフィルタしてしまうのもありだと思います。
さて、母集団である文書群を考え各トピックの意味を仮に以下のように定めます。
TOPIC0: 福祉・教育 TOPIC1: 健康 TOPIC2: ビジネス TOPIC3: 夢の実現 TOPIC4: 人
4.個別のドキュメントの分析
最後に、文書を指定してその文書のトピックがどのようになっているか分析しましょう。
対象となっている文書のコーパスデータをldaインスタンスに渡すだけです。
topic_label = [
"福祉・教育",
"健康",
"ビジネス",
"夢の実現",
"人"
]
target_record = 5 # 分析対象のドキュメントインデックス
for topics_per_document in lda[corpus[target_record]]:
print("{0:30s}{1}".format(topic_label[topics_per_document[0]], topics_per_document[1]))
こんな結果になります。この文書はビジネスの性質が強く出ている、というのがわかります。あとは閾値などを設けて実際にメタ情報として活用できます。
福祉・教育 0.025503321280086557 健康 0.025001172222024352 ビジネス 0.7468590388122892 夢の実現 0.02545997949638024 人 0.17717648818921963
終わりに
いかがでしょうか?膨大な文書に対して全体像にフィットしたカテゴリ情報・メタ情報を付与したいときにはなかなか使えそうな方法ではないでしょうか。
勿論、いざやってみると、データのクレンジング、ストップワード処理やステミングなど前処理の手間がそれなりにかかりますし、パラメータの調整もそれなりの難しさがあります。 またトピックの善し悪しの判断も必要です(トピックはできれば距離が離れているほうが望ましい)。こういったことを踏まえると到底「お手軽」とは言えませんが一度試してみるのは良いかと思います。
では、本日も最後までお読みいただきありがとうございました。
例によって当社では一緒に開発してくれるメンバーを募集しております。カジュアル面談も随時行っておりますので、「ちょっと話聞きたい」という方は、このブログのサイドバー下にあるアドレスか@YojiShirakiあたりにDMいただければと思います。採用サイトもありますので↓↓↓のバナーから是非どうぞ!ちなみに次回はデザインの話に戻ります。

