from polyglot.text import Text
from polyglot.detect import Detector
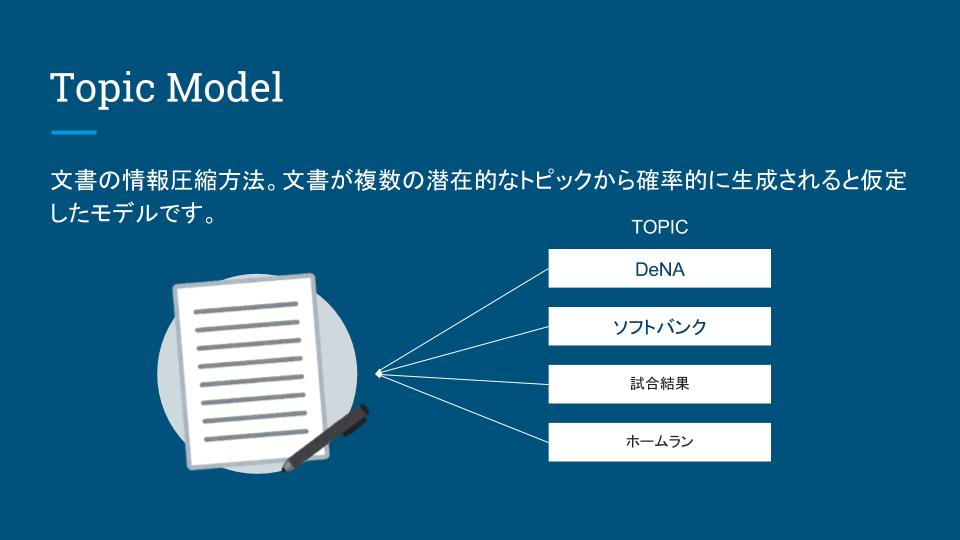
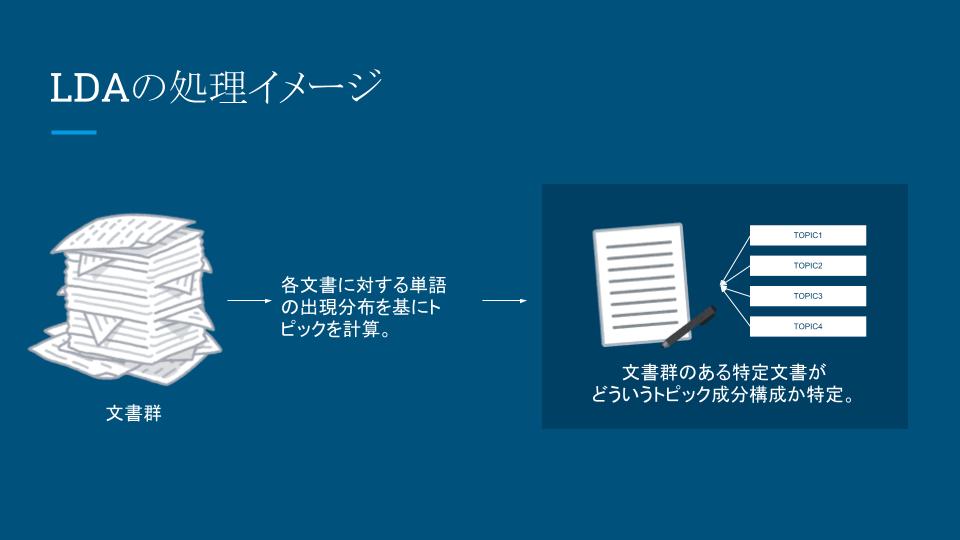
# 文書群(実際にはこういった文書が100万以上あるイメージです)
documents = [
{
'desc' : 'A beach safe for all those who want a carefree beach holiday. The HBT BELSAFER the HBT brings a mobile vault on the market, which offers a premium value protection with smart additional features.'
},
{
'desc' : 'The south curve must stay! The SOUTH CURVE is THE place of active FCC fans. Here come for generations the blue-yellow-white trailer together, showing brilliant choreography, are creative and unmistakable behind their team.'
},
{
'desc' : 'Darling4me - Video Dating and dating service on the smartphone. Find your soul mate on the smartphone with just one click on your smartphone. Darling4me is the first truly Video Dating app for your smartphone (Iphone, Ipad and Android). Darling4me dating service does not require lengthy questionnaires and extensive information from you to find your soul mate. They are tired of seeing it on various dating sites on the Internet images of singles that look quite different in reality? They also do not believe that you will find his true love with a questionnaire? Then try just the new Video Dating Darling4me! It has never been easier to find love. Get your partner suggestions from your environment and see with just one click on your smartphone, the videos of the singles that could be suitable for you. Live and real!'
}
]
for doc in documents:
desc = doc['desc']
text = Text(desc)
nouns = []
for tag in text.pos_tags:
word = tag[0]
word_class = tag[1]
if word_class != 'NOUN':
continueiflen(word) < 3:
continue
nouns.append(word.lower())
doc['nouns'] = nouns
print(nouns)
topic_N = 5# トピックの数(これは恣意的に設定できる。対象文書群が大きいなら数字は10にするなど)
lda = gensim.models.ldamodel.LdaModel(
corpus = corpus
, num_topics = topic_N
, id2word = dictionary
)
# モデルを保存する
lda.save('cf_lda.model')
# 見やすく出力for i inrange(topic_N):
print("\n")
print("="*80)
print("TOPIC {0}\n".format(i))
topic = lda.show_topic(i)
for t in topic:
print("{0:20s}{1}".format(t[0], t[1]))
出力はこんな感じです。
================================================================================
TOPIC 0
children 0.04091190129015311
community 0.03130555261697799
people 0.029479935059319066
school 0.02772734591535905
trip 0.024166451030072957
families 0.02161773848009083
food 0.021610873859255263
students 0.01979379324892966
funds 0.017129066919807687
donations 0.016645475281216793
================================================================================
TOPIC 1
family 0.05142340959037838
time 0.02913106744366217
life 0.027162997294828555
years 0.024956546073125124
home 0.01966655399836955
year 0.018690935949895755
bills 0.018176062282802562
cancer 0.017468175859926792
kids 0.016755068548548788
surgery 0.016417772028110674
================================================================================
TOPIC 2
cause 0.3400466352795431
progress 0.3288091973047845
supporter 0.326162187172668
name 0.002616388814580179
list 0.0007183396591630143
style 0.0001032523653516189
size 5.034349340074679e-05
time 1.8874650176037916e-05
business 1.802981647432903e-05
text 1.8023864292905654e-05
================================================================================
TOPIC 3
name 0.04493116909991208
dream 0.03237160912917436
team 0.026269755943711323
music 0.024893502207153875
time 0.01889772053109854
equipment 0.018581267347826023
http 0.017372070771627068
support 0.017230217254967435
girls 0.016372972121079955
year 0.016264355823729516
================================================================================
TOPIC 4
people 0.03610631244471521
business 0.0258750156278881
world 0.023791209653958246
life 0.02243440793115274
time 0.018039148524328114
way 0.015300038103529194
project 0.014480208478364773
years 0.01395798245176747
campaign 0.012818022865819834
work 0.011415802285745767