お久しぶりです、植木です。前回記事を書いてから、かれこれ一年が経ち、また当番が回ってきました。
現在も、ICPのエンジニアを担当しており、バックエンドとフロントエンド問わずに両方やってます。
はじめに
さて、今回はJS界隈では話題のDenoに関するトピックスです。
弊社でもSwaggerで設計した内容を実際のコードにきちんとエンドポイントに落とし込んでいるのかを確認するツールや、Slack botで活用しており、徐々に浸透が広まっております。
個人的にもコードレビューでの気になるコードの動作確認をDenoのReplで行ったり、書き捨てのコードが必要な時もJSでささっと書いてDenoで実行するケースは多いです。
Denoはこの一年でますます勢いを増し、deno.land/xを見てみると、サードパーティモジュールの数は約2000にも及んでいます。
今回は、そのサードパーティモジュールの中でも人気があったり、パフォーマンスを一番発揮するようなフレームワークはどれなの?という疑問に対して、比較検証した結果を紹介します!
準備
下記を使用して、検証しました。(インストール方法は割愛)
- Deno 1.8.2
- autocannon v7.0.5
autocannonでは、Req/Sec、Byte/Sec、Latencyを計測できるので、それを中心に測定していきましょう
Webフレームワークを選定する
個人的に運営しているdeno-x-rankingを活用しながら、最近人気がありそうな11個を選定しました。
deno.land/xではGithubのdescriptionまで見れないので、deno-x-rankingで読んでWebフレームワークと言えるか判断していきいました。
ノミネートはこちら。A-Z順に並べます
abc
alosaur
aqua
deno-drash ※ 通称はdrashですが、この記事ではリポジトリ名の方で統一します
dragon
mandarinets
oak
opine
pogo
reno
servest
この中では、oakが1番人気で聞いたことがある人も多いかもしれません。かく言う僕も心の中でもoakを上回るのはどれかなと楽しみです。
コードを書く
Hello worldを返すサンプルコードを1つづつ用意していきます。
ついでに、一言ずつコメントと、スター数とフォーク数(※2021/03/31時点)をつけて紹介していきます。計測結果だけ知りたい方は飛ばしてください。
abc
expressライクに書けて、分かりやすいです。2018年からあるフレームワークで、メンテされ続けてます。スター数も今回紹介する中では5番目とやや多め。
Star: 515 / Fork: 45
import { Application } from "https://deno.land/x/abc@v1.3.0/mod.ts"; const app = new Application(); console.log("http://localhost:8080/"); app .get("/", (c) => { return "Hello, World!"; }) .start({ port: 8080 });
alosaur
デコレーターで定義されてるタイプです。Javaのアノテーションとよく似てますが、JSでは定義するときはただの関数と変わりません @Controller
ロードマップがあるので、今後も機能追加されていくことでしょう。スター数は4番手。
Star: 515 / Fork: 45
import { App, Area, Controller, Get, } from "https://deno.land/x/alosaur@v0.29.3/mod.ts"; @Controller() // or specific path @Controller("/home") export class HomeController { @Get() // or specific path @Get("/hello") text() { return "Hello World!"; } } // Declare module @Area({ controllers: [HomeController], }) export class HomeArea {} // Create alosaur application const app = new App({ areas: [HomeArea], }); app.listen('0.0.0.0:8080');
aqua
今回紹介する中ではコード量が少なくシンプルです。こちらもExpressライクです。
READMEにあるベンチマーク紹介では、abcやdeno-drashを上回ると書いてあるので、期待が高まります
Star: 121 / Fork: 4
import Aqua from "https://deno.land/x/aqua@v1.1.0/mod.ts"; const app = new Aqua(8080); app.get("/", (req) => { return "Hello World!"; });
deno-drash
ドキュメントのチュートリアルがしっかりしてますDrash Land - Drash。ひっそりYoutubeもあります。
「サードパーティに依存しないHTTPサーバー」と紹介されてる通り、deps.tsの中をみてみると、https://deno.land/x/から始まるものが1つもありません
スター数は2番手。
Star: 806 / Fork: 24
import { Drash } from "https://deno.land/x/drash@v1.4.1/mod.ts"; class HomeResource extends Drash.Http.Resource { static paths = ["/"]; public GET() { this.response.body = "Hello World!"; return this.response; } } const server = new Drash.Http.Server({ response_output: "text/html", resources: [HomeResource] }); server.run({ hostname: "0.0.0.0", port: 8080 });
dragon
リポジトリ作成日が2020/11/29となっていて、かなり新しいです。Readmeのベンチマークに関する記載があり、そこではoakを上回っているので、期待を込めて選びました
Star: 61 / Fork: 9
import { Application, HttpRequest, HttpResponse, RequestMethod, } from "https://deno.land/x/dragon@v1.1.5/lib/mod.ts"; async function main(args: string[]): Promise<void> { const app = new Application(); const r = app.routes({ maxRoutes: 1 }); r.Path("/").withMethods(RequestMethod.GET).handleFunc( async function (Request: HttpRequest, ResponseWriter: HttpResponse) { ResponseWriter.withBody("Hello Dragon").end(); }, ); app.listenAndServe({ port: 8080 }); } await main(Deno.args);
mandarinets
MVCで、こちらもデコレーションが使われてます。
mandarineorgというorganizationで、orangeやmicrolemonという関連プロダクトがあります。
ドキュメントもかなりしっかりしてます MandarineTS
Star: 170 / Fork: 9
import { MandarineCore, Controller, GET } from "https://deno.land/x/mandarinets@v2.3.2/mod.ts"; @Controller() export class MyController { @GET('/') public httpHandler() { return "Hello World!"; } } new MandarineCore().MVC().run();
oak
サードパーティの中では一番人気なのがこれです。コードもスッキリしてます
Denoのメンテナでもある@kitsonkさんが主体で活動してるので、メンテナンスされていくことは確実でしょう。
Star: 3084 / Fork: 159
import { Application } from "https://deno.land/x/oak@v6.5.0/mod.ts"; const app = new Application(); app.use((ctx) => { ctx.response.body = "Hello World!"; }); await app.listen({ port: 8080 });
opine
こちらもexpressライクに書けるタイプです。
以前から、Reactのexampleをはじめexamples配下が充実しており、実装の際に参考になることでしょう。とはいえReactに関しては、aleph.jsが台頭する前は、と言うのがあるので、今だとaleph.js使うのが良いとは思います。
Star: 512 / Fork: 25
import { opine } from "https://deno.land/x/opine@1.2.0/mod.ts"; const app = opine(); app.get("/", function(req, res) { res.send("Hello World!"); }); app.listen(8080);
pogo
こちらもシンプルでいい感じで、routesの書き方もAdding routesで紹介されてるような書き方も自由です。
ReactとJSXもサポートしてます。
Star: 344 / Fork: 28
import pogo from 'https://deno.land/x/pogo@v0.5.2/main.ts'; const server = pogo.server({ hostname: '0.0.0.0', port : 8080 }); server.router.get('/', () => { return 'Hello World!'; }); server.start();
reno
Errorハンドリングがはじめから入っている分、少し長くは見えますが、複雑なところはないです。
そもそも標準ライブラリのhttp/server.tsを薄くラップする思想で作られているので、これが正しい姿と言えますね。
Star: 96 / Fork: 3
import { listenAndServe } from "https://deno.land/std@0.90.0/http/server.ts"; import { createRouter, createRouteMap, textResponse, NotFoundError, } from "https://deno.land/x/reno@v1.3.11/reno/mod.ts"; function createErrorResponse(status: number, { message }: Error) { return textResponse(message, {}, status); } export const routes = createRouteMap([ ["/", () => textResponse("Hello World!")], ]); const notFound = (e: NotFoundError) => createErrorResponse(404, e); const serverError = (e: Error) => createErrorResponse(500, e); const mapToErrorResponse = (e: Error) => e instanceof NotFoundError ? notFound(e) : serverError(e); const router = createRouter(routes); await listenAndServe( ":8080", async (req) => { try { const res = await router(req); return req.respond(res); } catch (e) { return req.respond(mapToErrorResponse(e)); } }, );
servest
Denoコントリビュータで、日本人(@keroxp)が作ってます。スター数も3番手。(すごい!)
デフォルト設定でログが出るので、公平を期すために今回はLoglevelをERRORで設定することで余計なログは抑えて、勝負する事にしました。
Star: 694 / Fork: 38
import { createApp, Loglevel, setLevel } from "https://deno.land/x/servest@v1.2.0/mod.ts"; const app = createApp(); setLevel(Loglevel.ERROR); app.get("/", async (req) => { const body = await req.respond({ status: 200, headers: new Headers({ "content-type": "text/html", }), body: "Hello World!", });; }); app.listen({ port: 8080 });
速度検証結果
レイテンシー分析
dragon、alosaur、aqua、deno-drash、oakのレイテンシーは平均値で全て50ms以内で安定して早いことが分かります。
また、99.0%においても50ms以内に返すことができているのは、dragonのみという結果でした
平均値
| Latency | Avg (ms) |
|---|---|
| dragon | 27.14 |
| alosaur | 32.01 |
| aqua | 32.2 |
| deno-drash | 32.96 |
| oak | 38.41 |
| reno | 86.67 |
| abc | 91.89 |
| pogo | 93.77 |
| mandarinets | 96.21 |
| servest | 144.38 |
| opine | 157.62 |

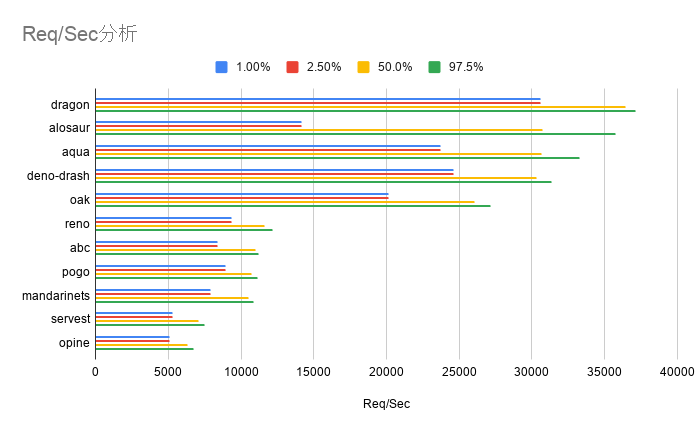
Req/Sec分析
ここでもdragon、alosaur、aqua、deno-drash、oakが速度が早く安定していることが分かります。
dragonとoakでは、1000rps程度違うので、この差は大きいです。
alosaurは、1.00%, 2.50%が上位5つで比べて低いので、たまにうまくリクエストを捌けていないようです
平均値
| Req/Sec | Avg(rps) |
|---|---|
| dragon | 36190.6 |
| alosaur | 30767.3 |
| aqua | 30584.6 |
| deno-drash | 29884 |
| oak | 25702.8 |
| reno | 11469.4 |
| abc | 10819.8 |
| pogo | 10604.6 |
| mandarinets | 10334.21 |
| servest | 6894.3 |
| opine | 6318.6 |
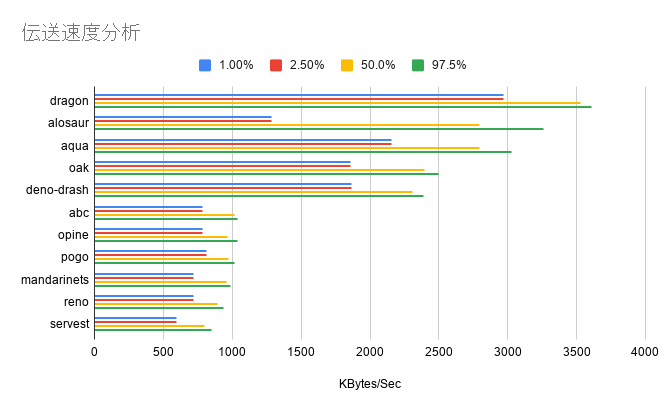
伝送速度分析(Byte/Sec)
ここでもdragon、alosaur、aqua、deno-drash、oakが速度が早く安定していることが分かります。
レイテンシー分析とReq/Sec分析では、deno-drash→oakでしたが、ここで初めてoak→deno-drashと順位が入れ替わりました。
平均値でdragonは、renoやservestの実に4倍のスコアが出ています。
alosaurは、1.00%, 2.50%が上位5つで比べて低いので、たまにうまく伝送できていないようです
平均値
| Bytes/Sec | Avg |
|---|---|
| dragon | 3510000 |
| alosaur | 2800000 |
| aqua | 2780000 |
| oak | 2360000 |
| deno-drash | 2270000 |
| abc | 1010000 |
| opine | 967000 |
| pogo | 965000 |
| mandarinets | 940000 |
| reno | 883000 |
| servest | 779000 |
検証時に発生したerror: Uncaught (in promise) BrokenPipe: Broken pipe (os error 32)というエラーに関して
下記のモジュールはで検証中に、実はautocannonの実行後にエラーが発生しました
alosaur
aqua
deno-drash
dragon
mandarinets
opine
reno
error: Uncaught (in promise) BrokenPipe: Broken pipe (os error 32) at handleError (deno:core/core.js:186:12) at binOpParseResult (deno:core/core.js:299:32) at asyncHandle (deno:core/core.js:223:40) at Array.asyncHandlers.<computed> (deno:core/core.js:238:9) at handleAsyncMsgFromRust (deno:core/core.js:207:32)
今回使用した、autocannonの-p/--pipeliningオプションを使用した際に起こるようで、Deno本体の問題かどうかの切り分けがされていない状態のIssueは存在しました。
(本題ではないこともあり、)今回の検証で発生した情報はIssueに提供しておき、情報を待つことにしました
結論
・パフォーマンスを存分に出す必要があるなら、dragonを選びましょう。
・パフォーマンスと人気度(今後もメンテナンスされる可能性が高そう)の両方を必要とするなら、oak, deno-drash, alosaur の中から、記法や機能差(ここは調査できてないのでご自身で調べてみてください)を基準に1つを選びましょう。
・上記2つに当てはまらない(ささっと、とりあえず動かしたいというような時など)パフォーマンスとコード量の両方を重視したいなら、aqua, oakがおすすめです。
Denoの今後の動き
これまで説明してきたWebフレームワークはdeno_std/httpを使用している前提の話でしたが、Deno namespace APIに直接httpが扱えるようになるPull Requestが出ています。
[WIP] feat: native HTTP bindings by bartlomieju · Pull Request #9935 · denoland/deno · GitHub
つまり、Denoのドキュメントで紹介されるように、
import { serve } from "https://deno.land/std@0.91.0/http/server.ts"; const server = serve({ hostname: "0.0.0.0", port: 8080 });
のようにimportしてから利用するのではなく直接、
Deno.http.createServer("127.0.0.1:8080")と書くことができるようになると言うことです。
これがmergeされることでパフォーマンスは上がるので、今回の検証結果に一泡吹かせる事になるかもしれません。 また、途中で紹介したエラーもstdに起因する原因であれば発生しなくなる可能性もあります
感想
使ったことがないWebフレームワークも多く、また最終的なパフォーマンス結果に差が思っていたよりあったので、検証してみて面白かったです!
中でもdragonとaquaはスター数も少なく、この記事を読むまで知らない人が多かった事でしょう!隠れたヒーローを見つけたような気分になりました。
今回の作業内容はこちらのリポジトリにあります。
github.com
至らない点や、足りないフレームワークを見つけたら、Issueをあげてリクエストするか、Pull Requestでコードベースで投げつけてくださると幸いです。
最後までお読みいただきありがとうございました。
アスタミューぜでは引き続き、一緒に働いてくれるデザイナー・エンジニア、さらにはDenoを使って活躍したい方を大募集中です!
下記に採用サイトもありますので、是非ご覧ください。








