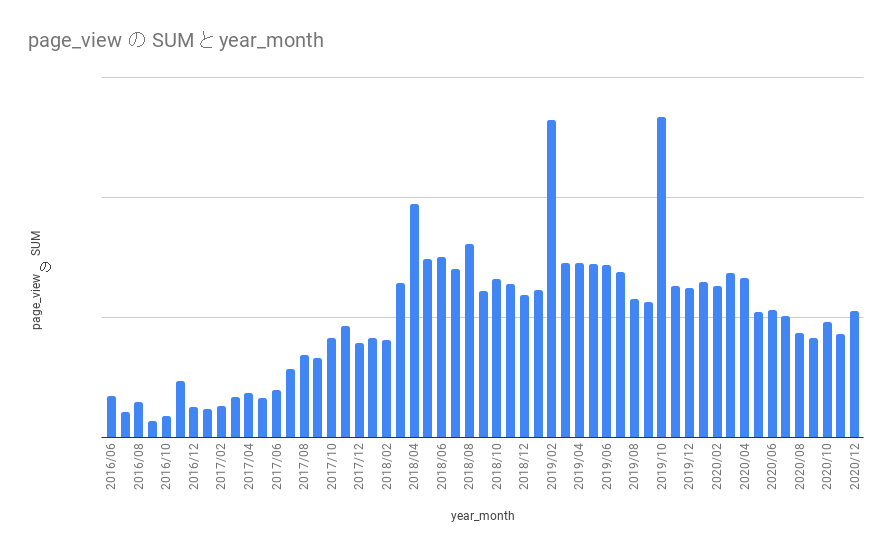
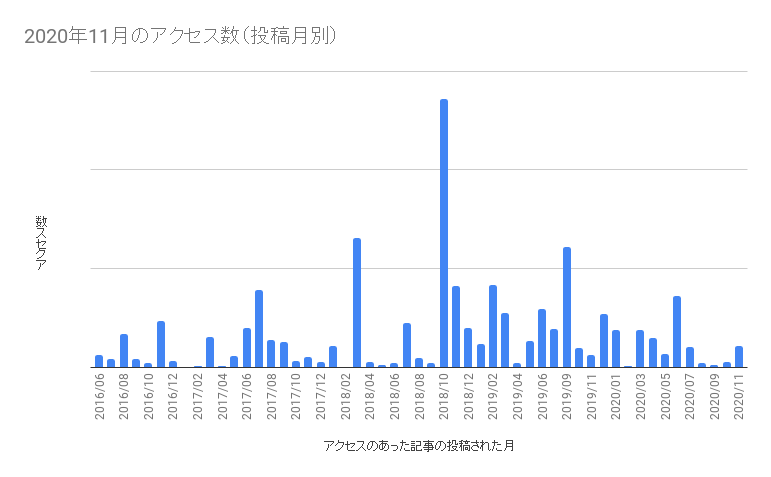
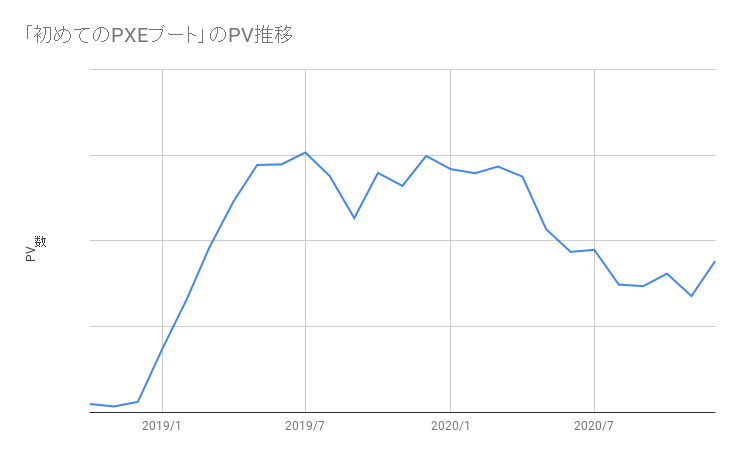
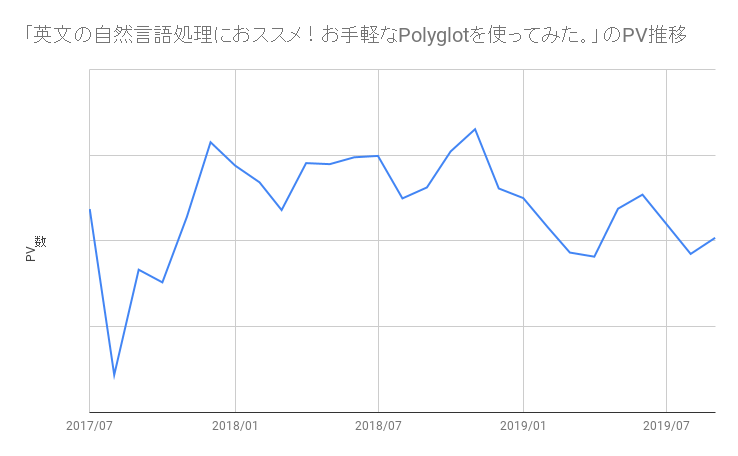
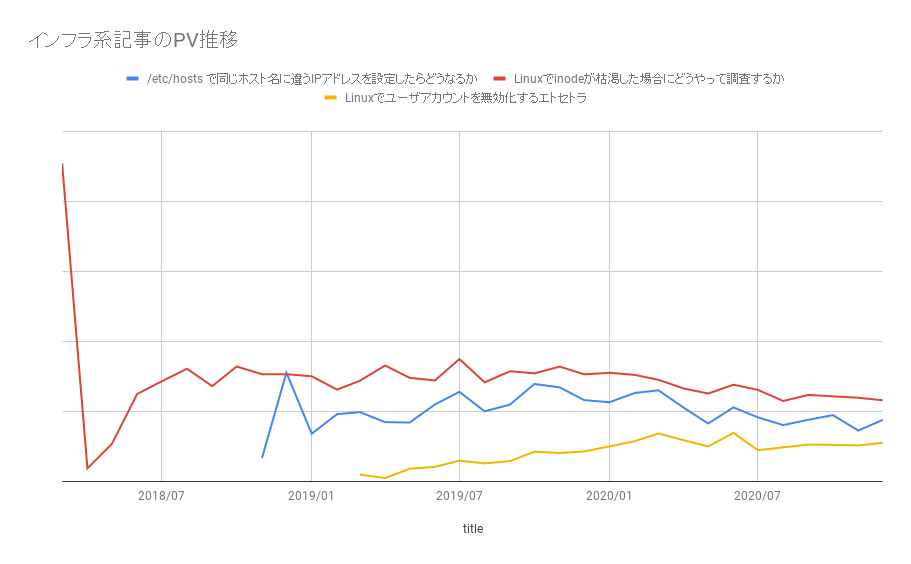
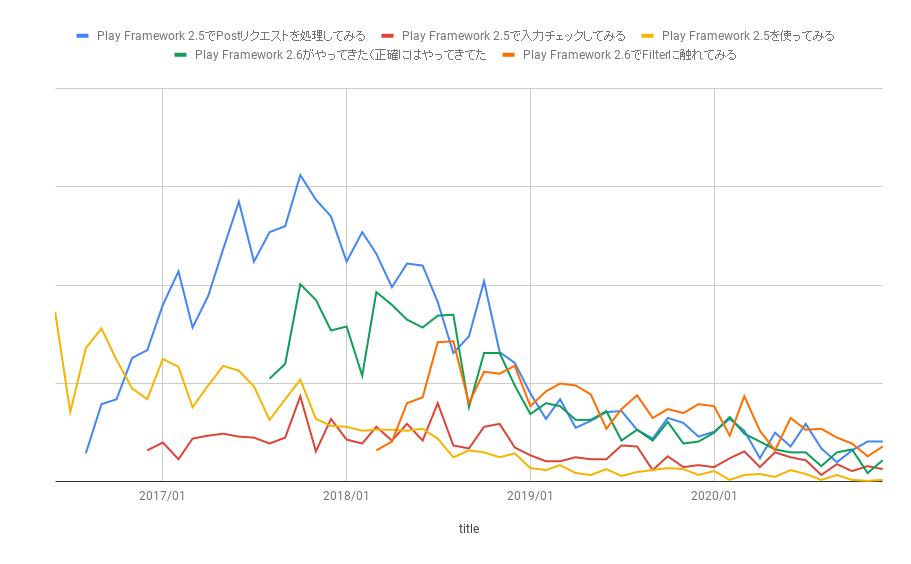
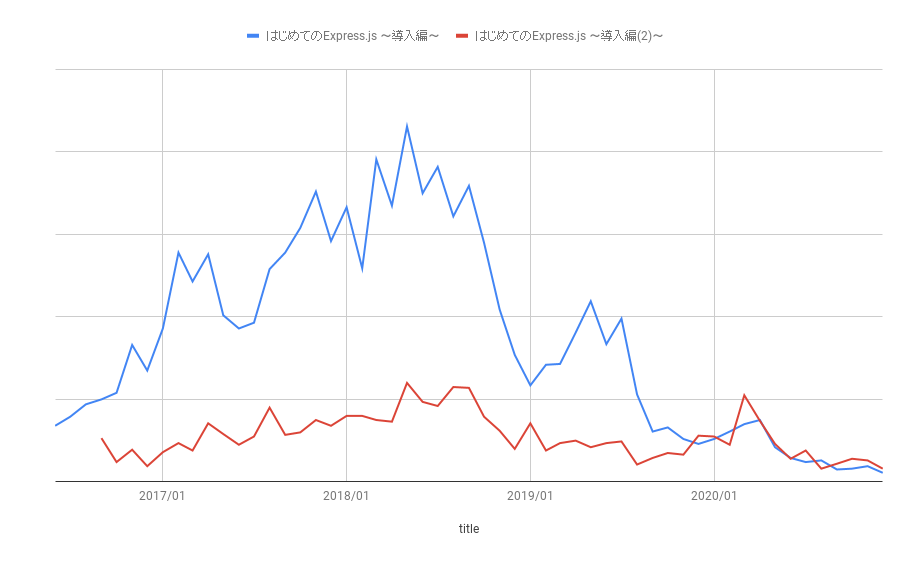
今回のブログ担当のt-sugaiです。今回、弊社のじんからインタビュー形式で、データエンジニアが何を考えているのか、という記事にしてはどうか、という提案があり、インタビューを受ける形になりますが、インタビュー形式でお送りします。
ーー今日はよろしくお願いいたします。
t-sugai:よろしくお願いいたします。
ーーt-sugaiさんは当社においてデータベース大臣の異名をお持ちです。これについてはいかがお考えですか。
t-sugai:物々しい二つ名なのと、自分自身は普通のデータベースの利用者だと思っているので、非常に恐縮です。
一方で、キャッチーな名前をつけていただいたことで、「データベースのことはt-sugaiに聞いてみようかな」というのが共有されているのは嬉しいです。
ーーさっそく本質的な質問から始めさせていただいてもよろしいですか。データベースってなんでしょう。
t-sugai:(しばらく宙を見つめてしまう)
現実問題として、「データベース」という語の利用は、非常にハイコンテクストでして、誰がどんな場面で発した言葉か、を非常に気にしてしまうのですけれども。
ーー話し手と受け手で齟齬があるということですね。
極端なことをいえば、プログラミングスクールで使われる場合と、図書館情報学の講座で使われる場合、などというとわかりやすいでしょうか。
前者は単純に「SQLで問い合わせができる、いわゆるRDBMS、おそらくはMySQLかPostgreSQL、もしかしたらSQLiteかOracle、SQL Serverかもしれない」あたりの具体物を表していることがほぼ明確です。
一方で、後者の場合にはもう少し抽象的で、なんならコンピューターシステムであること自体も仮定していないかもしれません。デューイ十進や日本十進分類法などの方法で図書が分類された物理的な目録、図書カードの整理された棚などの一式を以て「データベース」と表現している可能性もあると思います。
データエンジニアの周辺でも最近はKVSやNoSQL、DWHなども含めて、データの蓄積と検索ができるようなものを全部含んでいるような場合もありますし、単純なミドルウェアの話ではなくて、「データを蓄積/検索できるようにした一連のシステム」を「データベース」と呼ぶことも多いです。アスタミューゼの持っているイノベーションデータベースも、概ね「ある程度抽象化された一連のシステム」として認識されているかと思います。
ーー外側からデータベースを、利用者として見るときと、開発者が内側からデータベースを見るときに生じる齟齬を解決するためには、丁寧な意思疎通が必要になってくると感じています。そういった際に気をつけてらっしゃることはありますか。
t-sugai:データベースに限らず、いろいろなところでこの問題は話題に上がっているとおもいます。ソフトウェア開発一般、またはプロジェクトマネジメントなどの場合でもそうだと思うのですが、「お互いをリスペクトする」というのと、「より知っている方(開発者側)が歩み寄る」ということになりますね。
あとは、利用者というのが「SQLを書く人」なのか、「ORMを使ったアプリケーションコードを書く人」なのか、はたまた「綺麗にUIまでつくってもらった何かの検索システムを使う人」なのかによって、利用者に対する期待値も異なります。特に前者2つに関してはデータベースに関する知識をある程度持っていただきたいので、できる限り情報提供をしたり、キャッチアップのお手伝いをしたいと考えています。
ーーデータベース内の実体とそれらの間の関係は、人間のある種の世界認識を反映するものに当然ならざるを得ないと思うのですが、それについてはいかがですか。
t-sugai:まさにその通りで、データベースのベテランは必ず「テーブル設計ではなくて、まずはデータモデルを設計しろ」と言います。
データモデルというのは、つまり現実世界のものごとを「データ」という観点で抽象化するということです。例えば、現実の売買取引の場合、通常データベース化されそうな「何の商品を」「いくら(単価)で」「いくつ(数量)」、「何月何日何時何分何秒に」売ったのか、というような属性だけでなく、売り手や買い手の属性として、「店舗の住所」や「店主の名前、年齢、性別、家族構成 etc...」と、言ってしまえば無数の属性を想定することができてしまいます。その中で、「今回我々が気にしている属性はどれで、気にしても仕方ない属性はどれか」ということをひとつひとつ考えているわけで、これは世界認識の書き起こしに他なりません。
私自身は元々知識表現的な分野が好きで、例えば学生のころに友人に聞かれて面白いな、とおもったのが「ラーメンとは何か」っていう問いがあります。これ、うどんやちゃんぽんなどをうまく排しつつも、みんなが「ラーメン」だと思っているものを漏れなく内包的に表現する、というのはなかなか難しいんです。
似たような話で、こちらはもうちょっと有名な方が「カレーの定義は何か」ということを考えていて、「カレーとは、唐辛子を含む2種類以上の香辛料を使用し加熱調理された副食物の内で、おおよそ等量の米飯と共に食べた場合にそれぞれを単独で食べた場合より美味しくなる料理の総称である」という有名な一節があります。ただ、この定義で行くと「麻婆豆腐もカレーである」ということになるんですよね。
こういう、そもそも自分自身の世界認識を問い直すようなことを日常的にやる癖がある人、哲学とかが好きな人はデータベース設計に向いていると思いますね(笑)
ーー過去に質問応答システムの開発に携わっていた際に、適切な応答を生成するためにどのようなデータをどのような形態で保持しておくべきか、といった点について、質問とその応答の対象となる領域において、どのような知識を、すなわち世界認識を計算機上に保持しなければならないか、精密な設計が必要だったことを思い出します。その一方で、世界の見方を計算機上で表現するとともに、運用のためには、例えば頻繁に更新されるテーブルには、正確な表現というよりはむしろ運用のための工夫が必要といったジレンマがあるのではないかと思うのですが、こういった点についてはいかがでしょうか。
t-sugai:テーブル設計で一番頭を悩ませる部分ですよね。正確な表現というのは基本的に論理の世界、頭の中の世界だけのことを考えていればいいのですが、運用するときには現実世界の物理法則に縛られます。これもひとつのインピーダンスミスマッチだと考えることもできると思います。
ここで重要になってくるのが計算機に対する知識で、必要とするシステムの仕様だと、応答性能はどのくらいの時間に納めなければならないか、使えるお金がいくらで、そうすると使えるハードウェア性能はいかほどのものか。データの量と複雑さ、検索質問の複雑さはいかほどか。それらの制約問題を解くとしたらどこを譲らずに何を諦めるのか……突き詰めるとどんな仕事でも同じような判断をしているとは思いますし、かなり抽象的な話になってしまって恐縮なのですが、データベースも同様なんです。ということで。
ーー様々な制約の中で、できるだけ最適に近い解を探し出すのはすべての仕事に共通するものということですね。ところで、個人的にとても印象に残っているのは、ある眼鏡店に、先日17年ぶりに訪れたときに、17年前の私のデータがデータベースからちゃんと出てきたことです。これは恐るべきことだと思うのですが、実際のところどうでしょう。
t-sugai:これに関しては、人によって感じることが異なりそうですね。役所での仕事や、基幹システムに携わっている方なら、エンジニアでなくとも「それが仕事なんだから当たり前だろ」と言われるのじゃないでしょうか。でも、特にWeb系のエンジニアなどをやってると「そんな昔のデータを取っておくなんて正気か?」という気持ちになるのもすごくよくわかります。
前職では、PC98の時代から量販店でエンドユーザー向けに売られるようなパッケージのソフトウェアを開発・販売していたのですが、その頃にハガキでユーザー登録された人のデータなども顧客DBにはきちんと残っていると聞いたことがあります。後にその会社がWebサービスを提供するようになってからアカウント作成した人も、ハガキでユーザー登録した人も、等しく顧客DBで管理されるということで、基幹システム的なものをつくるというのはエンジニア的な観点からすると恐ろしさは感じますよね。究極的には、自分が死んだあともデータが残るつもりで設計しなければいけないですし。
ーー眼鏡店としては、単に新しい眼鏡のデザインを考えることだけではなくて、顧客の視力などのデータを維持し続けることも実は欠かすことのできない事業ということですね。眼鏡店であれば顧客の名前や視力、老眼といったことも考えられますから年齢といったデータが当然想定されうると思うのですが、その一方で、それらを定義するER図の設計は率直に言ってとても難しいと感じます。なぜこんなに難しいのでしょうか。
t-sugai:ER図の設計というのは、一般に論理設計と言われている部分、ないしは論理設計およびテーブル定義あたりを指しているということでいいですね。
このER図の設計は、「サービスが終了するなどしてデータベースが役目を終えるそのときまで、答え合わせができない、ないしは答え合わせにさらされ続ける」という性質をもっています。
しょうもない設計をしたとしても、アクセス数も増えず、テーブルの行数も増えず、数年未満でお役御免になる、というようなデータベースであれば、アプリケーションから使いやすく、アプリケーションの実装者に理解しやすければ別にそれでいいとも言えます。
一方で、非常にしっかりとした正規化ができているように見えても、複雑なJOINが必要になりすぎるとか、行数がめちゃくちゃ増えるとか、はたまたサービスを拡張しなければいけないときにうまく追従できないとか、そういうことがあると「イマイチなER設計」って思われてしまうでしょう。
そんなわけで、本質的に答え合わせに年単位の時間がかかったり、これは職場にもよるのでしょうが、アスタミューゼを含めて私が経験した職場では、「日々さまざまなDBのER図の設計を行う」ということはなく、新規サービスの立ち上げ時であったり、DBを改修するような大幅な拡張があるときにだけしか設計をするチャンスそのものが来ないので、「前回の反省を生かしてやってみる経験」自体を非常に積みにくいという構造があると思っています。
くわえて、対象のデータベースがどのくらいの期間使われるのか、なんの目的で使われるのか、当初の目的外の使われ方をするかどうかをどこまで織り込むべきか……常に中長期的な視野を求められることになります。また、先ほどの眼鏡屋さんの例でもあったように、データは10年20年と使われ続けることはまれではありません。例えば10年前といえばAWSが日本に上陸した直後くらいのことですし、20年前にはまだ光ファイバーによるインターネットは日本の一般家庭にとっては珍しいものでした。その間にストレージの価格も下がりましたし、そもそも磁気ディスクからSSDが主流になることでランダムアクセス速度はかなり速くなりました。そういった計算機やネットワーク自体の技術革新などもあり、ボトルネックの場所やコストがかかる場所というのが時代とともに変わってきます。つまり、「よいER設計」を目指すというのは、本質的に現在と未来、場合によっては過去を徹底的に考えるという仕事になる、というところが難しく感じる所以ではないでしょうか。
ーーお話を伺いますと、データベースに精通するためには、実に様々な能力が必要になってくると感じます。どういう風に勉強していけばよいのか、特にこれからこの道に入る方に向けて、最後にぜひご助言をいただけませんか。
t-sugai:私自身もそんなに偉そうなことを言えた立場ではなくて、たまたま、時代と、与えられた仕事と、自分の性格がマッチしたところに居させていただいているだけ、と思っています。
先ほども申し上げたとおり、小手先の知識やノウハウは世界全体の技術革新に呑み込まれて使えない知識になってしまいがちです。一方で、計算機がデータを処理する基本的な仕組みなど何十年も変わらないものはあります。基本的なデータモデリングやデータベースの内部構造を学ぶことはおすすめです。あとは、オブジェクト指向のクラス設計の仕方などを学ぶのもデータモデリングの助けになると思いますね。
ーー今日はどうもありがとうございました。
こちらこそ、ありがとうございました。 なかなかお話しする機会がないような話ではありましたが、よく「データエンジニアってどんな仕事をしているの?」というようなことを聞かれて何を答えるべきか迷ってしまうのですが、じんさんが良い質問をしてくださるので、普段あまりできない話ができてよかったな、と思います。
アスタミューゼでは、データエンジニアを積極募集中でございます。特にこの話が面白いなと思っていただいた方、もっと詳しく話を聞いてみたいなと思った方など、カジュアル面談からでもウェルカムです。下記バナーよりどうぞお声がけください。