
ご挨拶
どうもお久しぶりです、gucciです。
気づけばもう12月も半ば…今年は本当に色々なことがあった年でしたね。
新型コロナによってこれまでの日常が一変し、当たり前だったものが当たり前でなくなるという本当に大変な年だったと思います。
私の好きなプロ野球ももちろん多大な影響を受けて、シーズンの開始が遅れ、無観客試合や手拍子での応援など、これまでとは異なるシーズンでしたが、何はともあれ無事にシーズンが終わることができたのは本当に素晴らしいことだと思います。
データエンジニアとしてやってきて
さて、そんな中で私はデータエンジニアになり2年が経ちました。
(入社して1年弱アプリエンジニア〜その後データエンジニアにジョブチェンジ)
弊社はとにかく様々なデータを集めています。
技術情報と他のデータを組み合わせたり、新しい分析手法を用いたり、独自の切り口で分類を行なったりすることで、弊社にしかできないソリューションを提供しております。
非常に優秀なデータアナリストがおりますので、分析するためのデータを我々データエンジニアが整備していくといった塩梅でございます。
これまでデータを色々な形で料理できるようにあれこれ設計・整備して参りましたが、おやおや、データを実際に使う側にも少し興味が湧いてきました。
そこで今回は、
「データ分析ことはじめ 〜はじめてのデータ分析やってみたよ〜」
というお題でお送りしたいと思います。
ちなみに、本当に初歩の初歩のことしかしないので、今回の内容はどちらかといえば非エンジニア向けのライトな内容です。
「データで分析っていってもまったく想像がつかない!」
「プログラミングでデータを使うと何ができるの?」
「野球が好き!」
という方におすすめです。
そうだ、野球のデータを使ってみよう
さて、データの分析をやってみようかなと思ったものの何を題材にして良いのかさっぱりわかりません。
悩み抜いた末に、日頃からこっそり集めていたプロ野球のデータを活用してみることにしました。
それでは簡単クッキング!!
使うもの
- プロ野球のデータ: csvファイル
- 実行環境: JupyterLab
- データごにょごにょ: Pandas
- 可視化ライブラリ: Plotly Express
プロ野球のデータ
いつもお世話になっているサイトがこちらの 「プロ野球データFREAK」さんです!!
こちらのサイトから「打者成績」「選手一覧」のデータを拝借させていただきました。
いつもありがとうございます。
実行環境
今回 python で分析を行なっていきます。
JupyterLab は Jupyter Notebook の進化版で、ブラウザ上で動作するプログラムの対話型実行環境です。
簡単に実行結果が確認でき、またグラフなどの描画も画面上でできるのでデータ分析には欠かせないツールと言えそうです。
データごにょごにょ
データ分析といえば Pandas (実はあまり使ったことがなかった)。
Dataframe という「表」でデータを扱うことができますので、とりあえずこいつでやっていきましょう。
可視化ライブラリ
今回はいわゆる有名な Matplotlib でなく Plotly Express というのを使っていきます。
弊社自慢の若手超優秀機械学習エンジニアのNくんが以前紹介されていたので、使ってみたくて選びました。
元々は Plotly というオープンソースのデータ分析・グラフ可視化ツールがあって、それのラッパーライブラリが Plotly Express だそうです。
より簡単にインタラクティブな描画ができるという優れモノです。
3Dやアニメーションも使えるみたいなのでなんだかとっても良さげ。
ただ、JupyterLab で描画すると最初は真っ白で何も表示されなくてビビります。
ちゃんとチュートリアルを読まないとですね。
給料泥棒を探せ
それでは、さっそくやっていきましょう。
- 2020年の年俸
- 2020年の成績
これらを組み合わせて可視化することで、給料泥棒お金を貰っている割にあまり結果を出せていないのは誰か、というのを調べちゃいましょう。
今回は打者の指標としてはOPSを用います。
OPS(オプス、オーピーエス)は On-base plus slugging の略であり、野球において打者を評価する指標の1つ。出塁率と長打率とを足し合わせた値である。
いっぱい塁に出たり長打を打てる人が打者として優れているよね、って指標です。
1を超えたら本当にすごい。
ここからは簡単にコードのご紹介!!(いい感じにパスとか汲んでくださいませ)
必要なライブラリの読み込み
import plotly.express as px import glob import pandas as pd import re
CSVデータ読み込み
# 2020年の打者成績一覧を読み込み df_all_batter_stat_2020 = pd.read_csv('{適切なパス}/Baseball/Batting/2020_stats.csv', sep = ',') # 2020年の各球団の選手一覧を読み込み # 「2020_{チーム名}.csv」で格納してある dir_path = '{適切なパス}/Baseball/Player/' all_files = glob.glob(dir_path + "2020*.csv") # 一つ一つのデータを読み込んで dataframe に追加していく(その際チーム名も追加) df_all_player = pd.DataFrame() for filename in all_files: df = pd.read_csv(filename, sep=',') team_name = re.sub('\d+_', '', filename.split('/')[-1].replace('.csv', '')) df['チーム'] = team_name df_all_player = pd.concat([df_all_player, df]).reset_index(drop=True)
打者成績一覧と選手一覧とがっちゃんこ
df_all_batter_data_merged = \ pd.merge(df_all_batter_stat_2020, df_all_player, how='inner', on=['選手名', 'チーム'])
'年俸(推定)' の文字列を'年俸(万円)'の数値に変換
OPSを算出して dataframe に追加
df_all_batter_data_merged['年俸(万円)'] = \ df_all_batter_data_merged['年俸(推定)'].str.replace(',', '').str.replace('万円', '').astype(int) df_all_batter_data_merged['OPS'] = \ df_all_batter_data_merged['長打率'] + df_all_batter_data_merged['出塁率']
全選手表示すると大変なことになるので、
『規定打席を超えた人(372打席)または年俸が1億円より多い人』を抽出
df_all_batter_data_merged_over_10000 = \ df_all_batter_data_merged[(df_all_batter_data_merged['年俸(万円)'] > 10000) | (df_all_batter_data_merged['打席数'] > 372)]
いざ、散布図を表示
fig = px.scatter(
df_all_batter_data_merged_over_10000,
x='OPS',
y='年俸(万円)',
text='選手名',
color='チーム',
size_max=30,
height=500,
width=800,
size='本塁打',
color_discrete_map={
'巨人': '#F97709',
'阪神': '#ffff00',
'広島': '#FF0000',
'中日': '#00008b',
'DeNA': '#00bfff',
'ヤクルト': '#7cfc00',
'ソフトバンク': '#f9ca00',
'オリックス': '#b08f32',
'日本ハム': '#02518c',
'ロッテ': '#221815',
'西武': '#102961',
'楽天': '#85010f'
}
)
fig.show()
その結果がこちら↓↓
いかがでしょう!!
この描画されたグラフ、マウスホバーで情報がでたりドラッグでズームインとかできちゃうんです!!
すごいお便利。
ちなみに、円の大きさが本塁打の数を表しています。
本当はもっと大きく出したかったのですが、サイトのページサイズの関係でこの形になりました…。
こちらの画像の方が見やすいかもしれません。
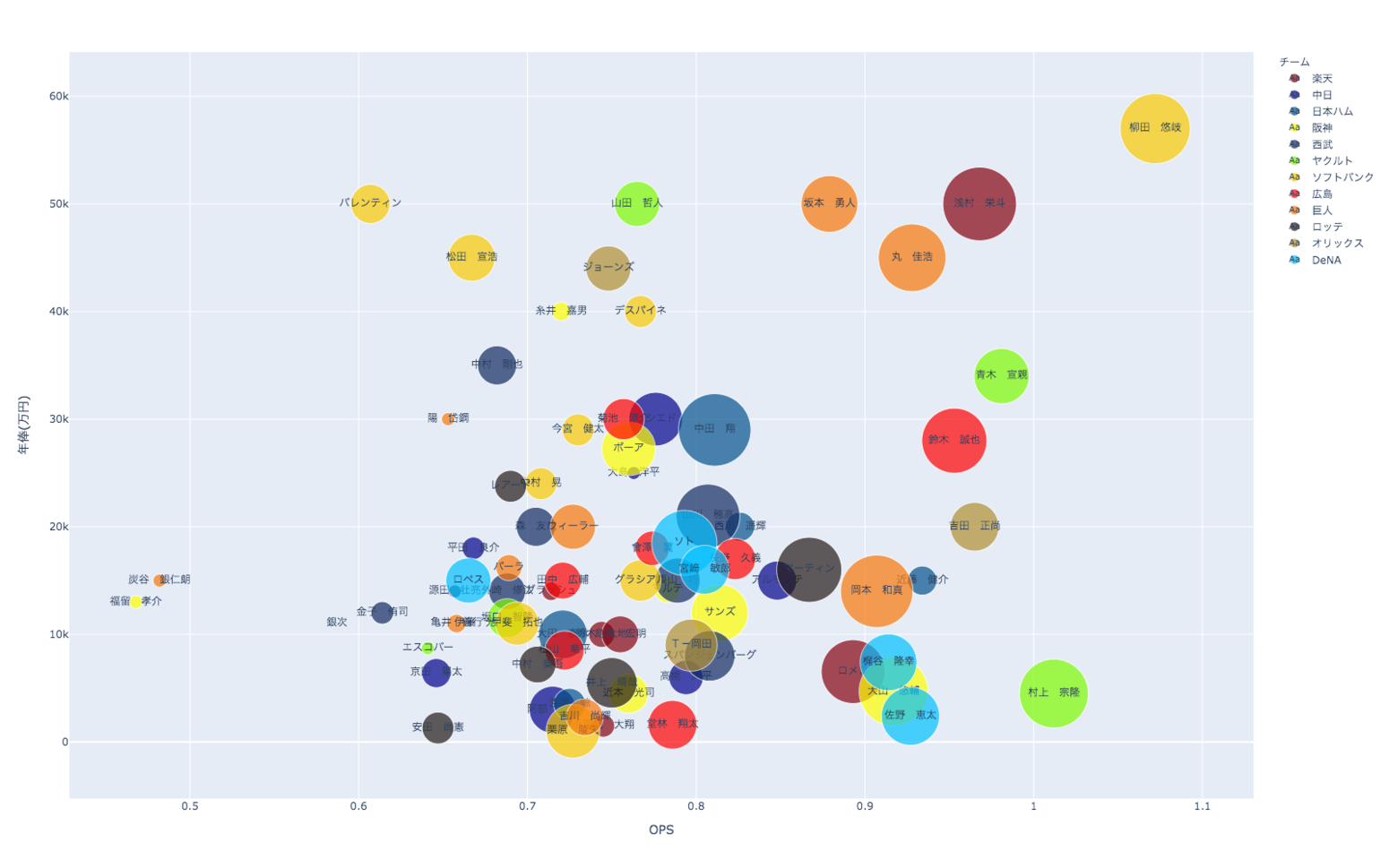
この散布図を見るだけで、
- 図右上:期待通りゾーン
- 柳田えぐい(一番年俸をもらっていて一番OPSが高い。すばらしい。)
- 図左上:年俸の割にOPSが高くないゾーン
- バレンティンがちょっと…年俸の割に…残念…
- 図右下:年俸の割によくやっているゾーン
- 村上くんは年俸の割にものすごいOPS
といったことが簡単にわかってしまいました。データを可視化するってのはすごいことですね。
これまでの貢献やOPS以外での活躍というのももちろんありますので一概には言えませんが、一つの見方としては面白いですね。
もうすっかり分析した気分になれちゃいます。
きちんとお給料もらってる?
さぁ乗ってきたところで、今度は活躍に応じてきちんと年俸が支払われているのかチェックしてみましょう。
前述の検証では、2020年の年俸と2020年の成績を使いましたが、
本来年俸というのは結果に対して「よう頑張った!!次も期待してるで!!」の側面が強い(成果)と思いますので、ためしに1年ずらして計算してみましょう。
- 2015〜2019年の成績の平均
- 2016〜2020年の年俸の平均
これらを使ってみます!! 基本的にはほぼ同じコードですので、新しいとこだけ書いておきます!!
集約して平均をだす
grouped_batter_detail = df_all_batter.groupby(['選手名', 'チーム'], as_index=False) grouped_batter_detail_avg = grouped_batter_detail.mean()
新しいのはこの子ぐらいでした。
5年に増やしたことによりさらに選手がごちゃくつので、
『平均400打席を超えた人または平均年俸が2億円より多い人』に条件を変更して・・・抽出!!
その結果がこちら↓↓
いかがでしょう!!
いちおおっきいのも貼っておきます!!
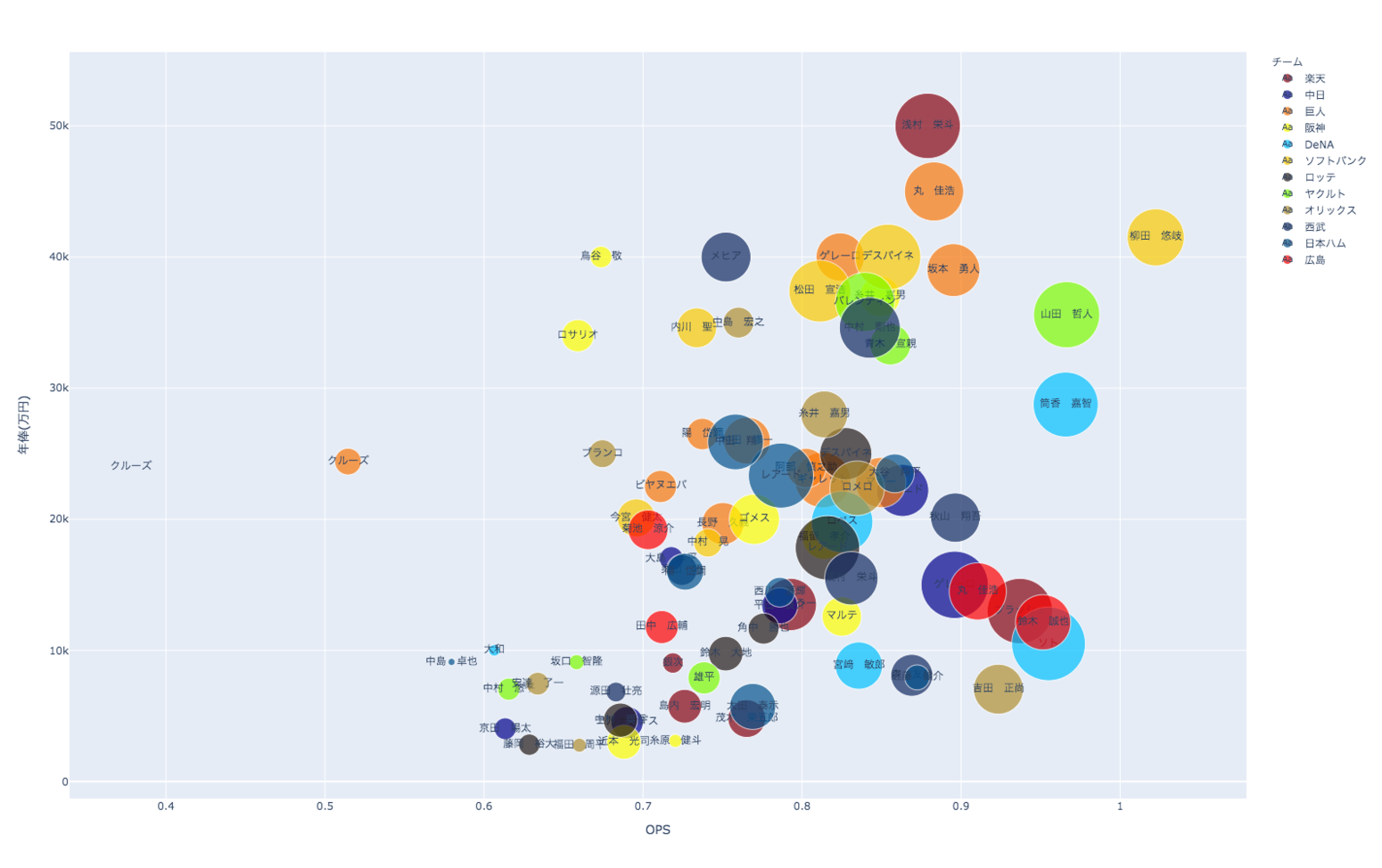
この散布図からは、
- 図右下の広島の丸選手が、図右上の巨人に移籍してしまうのも仕方がないかも…
- 近似曲線をイメージすると、やはり全体的にソフトバンクと巨人はそれよりも上にいそうな気がする…
- 気のせいかもしれませんが、中日は少し給料が低めなイメージが…
といったようなことがパッと思いつきますね!!
(個人の考えなので、ご気分を害された方がいらっしゃいましたら申し訳ございません。)
まとめ
いかがだったでしょうか。
大した分析はできていませんが、データを元にパッと可視化するだけで新たな気付きや発見があるというのが体験できたかと思います!!
今回はほんの一部の可視化〜分析でしたが、機械学習とかも絡めて予測できたらさらに幅が広がりそうですね!!
最後に、アスタミューゼではアプリエンジニア、デザイナー、プロダクトマネージャー、データエンジニア、機械学習エンジニアなどなど絶賛大募集中です!!
どしどしご応募ください!!お待ちしております!!
最後までお読みいただき、ありがとうございました!!
