この記事は 自然言語処理 Advent Calendar 2020 の25日目の記事です。
こんにちは、rinoguchi です。今年の4月に こちらの記事 を書いて以来、半年ぶりの投稿になります。
当社では、特許・研究課題・論文など多くの知的財産データを保持しています。これらのデータを活用するには、データに含まれる同一組織・同一人物に対して同一IDを付与してデータをグルーピングすることが必要であり、この作業のことを名寄せと呼んでいます。
今回はこの名寄せの仕組みについて紹介したいと思います。
大まかな処理フロー
当社では名寄せ処理を、まずそれぞれのデータソース(例えば特許や論文など)の中で実行し、次に異なるデータソース間で実行することで、最終的に組織ID・人物IDに対して特許・研究課題・論文などを紐づけたデータを生成しています。
とはいえ、データソース内名寄せもデータソース間名寄せも仕組みとしては同じで、以下の4つのステージで構成されています。
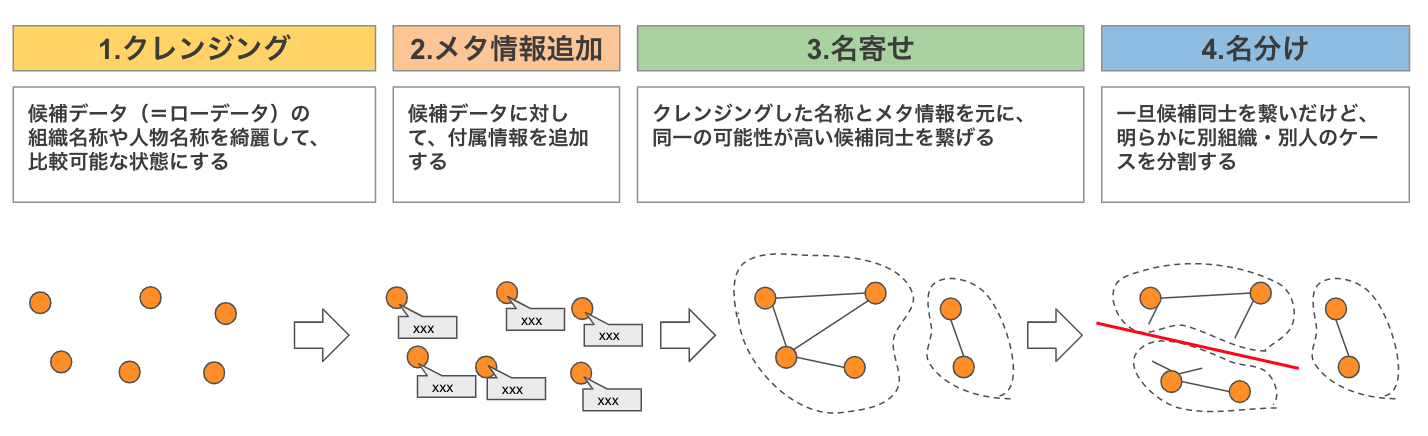
ここからは4つのステージについて、特定のデータソース内の人物名寄せを行うイメージで、処理内容を説明していきます。
1. クレンジング
クレンジングステージでは、生データに含まれる組織名や人物名を綺麗にして、プログラムで比較可能な状態にしていきます。
まずは、以下のような形で生データを候補データとして取り込みます。候補IDは、例えば特許の場合「出願番号×人物名」の組合せに対して一意になるように採番した値です。
| 候補ID | 生データID | 人物名(英) | 人物名(ローカル) |
|---|---|---|---|
| c01 | r01 | TAKAHASHI ICHIRO | 高橋 一郎 |
| c11 | r01 | Yamada Jiro | 山田 二郎 |
| c02 | r02 | Pf. TAKAHASHI ICHIRO | 高梁 一郎 |
| c03 | r03 | Takahasi Ichiro | |
| c04 | r04 | 髙橋一郎 |
クレンジングステージでは、例えば以下のような変換処理を地道に行っていきます。
- 名称の単純正規化(半角化、大文字化、不要記号などの除去)
- 不要文字除去(部署名、役職名など)
- 日英判断(日本語名称欄に英語が入っていたら英語名称欄に移動)
- 姓名分割(わかち書き)
- 英語翻訳(社内で保持している辞書およびGoogle Translate API)
- エイリアス変換(組織のみ。社内マスタおよび公開データを利用)
クレンジング後のデータは以下のような感じになりました。ここまでくれば、人物名(英)を元に同一人物の可能性が高い候補IDをグルーピングできそうです。
| 候補ID | 生データID | 人物名(英) | 人物名(日) | 処理内容 |
|---|---|---|---|---|
| c01 | r01 | TAKAHASHI ICHIRO | 高橋 一郎 | - |
| c11 | r01 | YAMADA JIRO | 山田 二郎 | 大文字化 |
| c02 | r02 | TAKAHASHI ICHIRO | 高梁 一郎 | 不要文字除去 |
| c03 | r03 | TAKAHASI ICHIRO | 日/英判断、半角化 | |
| c04 | r04 | TAKAHASHI ICHIRO | 髙橋 一郎 | 姓名分割、翻訳 |
2. メタ情報追加
クレンジングステージで名称が綺麗になったら、次は候補IDに対してメタ情報を追加していきます。
メタ情報は様々なデータソース(特許や論文など)を同じデータモデルで扱えるように、ある程度抽象化した名前(開始日、タイトルなど)にしてあります。
単純追加
生データに紐づく属性情報は、生データIDをキーに検索・抽出して候補IDに付加します。
例えば、共同研究者や組織名はそれだけである程度同一と判断できる非常に重要なメタ情報ですし、開始日もあまりに離れている場合は別人の可能性が高まりますので重要です。属性情報自体は数多くあるのでその中から重要そうなものをピックアップして取り込んでいきます。
| 候補ID | 生データID | 人物名(英) | 共同研究者 | 組織名 | 開始日 | タイトル | ... |
|---|---|---|---|---|---|---|---|
| c01 | r01 | TAKAHASHI ICHIRO | [YAMADA JIRO] | A会社 | 2020-01-01 | 〇〇に関する研究 | ... |
| c11 | r01 | YAMADA JIRO | [TAKAHASHI ICHIRO] | B会社 | 2020-01-01 | 〇〇に関する研究 | ... |
| c02 | r02 | TAKAHASHI ICHIRO | [ ] | A会社 | 2019-01-01 | ××技術について | ... |
| c03 | r03 | TAKAHASI ICHIRO | [YAMADA JIRO] | A会社 | 2008-01-01 | △△について | ... |
| c04 | r04 | TAKAHASHI ICHIRO | [ ] | C会社 | 1995-01-01 | □□について | ... |
タイトル抽出・ベクトル化
タイトルや本文も人間が判断する時にはかなり参考になりますが、そのままでは機械的には比較できませんので、タイトルはキーワード抽出、本文はベクトル化しました。
- 事前処理(小文字化、stopword除去、ステミング、単語分割)
- doc2bowを使ってBoW化(コーパス化)
- TF-IDF(gensimのTfidfModel)で、単語の特徴度を計算
- => 特徴度が一定以上の単語をタイトルキーワードとする
- LSI(gensimのLsiModel)で、300次元に圧縮
- => 本文ベクトルとする
自分は自然言語処理に詳しくないのですが、社内の自然言語処理の専門家である じんさん に相談したところ、特許や論文などのデータは特徴的な単語が使われていることが多く、それだけでかなり同一性を判断できるので、TF-IDFを用いるのは理にかなってるというアドバイスをもらいました。
実際のデータで検証したところ、タイトルキーワードや本文ベクトルから同一性が高いと判断したものは、人間の判断をかなりトレースできていることも分かりました。
少しシステム的なことを言及すると、このTF-IDFおよびLSIを用いたベクトル化の処理は、何も考えずに数億件のデータに対して適用すると計算量が大きくなりすぎますので、システム的には以下の2点を工夫をしました。
- 同一可能性が高いデータをグルーピングして、そのグループの中でベクトル化する
- イメージ的には「人物名(英)のイニシャルが同じ」ものをグルーピングする感じ
- Nが小さすぎるとベクトルが偏るので、グループを足し合わせて N=50000 ぐらいになるように調整
- グループ毎のベクトル化の処理を、Apache Spark 環境のフルマネージドサービスであるDataproc上で並列実行する
- 詳細は以下の記事で以前紹介してますので興味があればご覧ください
- PythonからDataprocを操作してシームレスに並列処理を実現する - astamuse Lab
これにより、1億件を数日で処理できるようになりました。
3. 名寄せ
名寄せステージが全体の本丸的な位置付けなのですが、同一の可能性が高い候補同士をつなぎ合わせる処理を行います。

同一の可能性がある候補同士を連結(組合せを列挙)
これは、同一の可能性がある候補IDの組合せを抽出するという処理になります。後続の処理でこの組合せ一つ一つに対してスコアリングを行うのですが、その際の計算量を抑えるための処理になります。
やりたいことは「人物名(英)の編集距離が閾値以下 or イニシャルが一致」するような候補IDを組合せを抽出するだけなのですが、この組合せを抽出する処理自体がかなりの計算量になります。
n個の候補IDから2つを取り出す組合せの数の計算式は なので、例えば1億件の候補IDが存在する場合、
1億 × (1億 - 1) / 2= 約5000兆 回の計算(比較処理)が必要になります。
この計算量を現実的な時間で終わらせるため、大きく3つ試してみました。
- BigQuery上でSQLで比較する【不採用】
- => 1億件×1億件のcross join。CPUがオーバーフロー
- グラフDB(neo4j)に突っ込んで、条件に一致するサブグラフを抽出する【不採用】
- => 試しに15万ノード3億エッジぐらいで試したが応答なし
- Dataprocを利用し、pysparkで分散処理【採用】
- => 現実的な時間で結果が返る
ここでも結局、分散処理を導入して解決しました。
結果として、一番データ件数が多い特許のケースで、同一の可能性がある組合せの件数は数百億件になりました。
候補の組合せ(エッジ)に対してスコアリング
候補の組合せを列挙できたので、次は各組合せのスコア(同一可能性)を数値化していきます。
この部分は、データソースによっても利用できるメタ情報が異なり、後からメタ情報を追加するケースもありそうなので、比較ルール(使用するメタ情報と比較ロジックのセット)をプラグインのように差し込めるように設計しました。
ここで比較ルールは例えば以下のようなもので、これらの比較ルールは互いに依存関係はなく独立して計算可能にしてあります。
- 比較ルール1: 本文ベクトルの類似度
- 比較ルール2: 共同研究者の一致
- 比較ルール3: 開始日の近さ
それぞれの比較ルールの処理結果が出たら、最後にこれらの数値を元に総合的なトータルスコアを算出します。
| 候補ID FROM |
候補ID TO |
比較ルール1 スコア |
比較ルール2 スコア |
... | トータルスコア |
|---|---|---|---|---|---|
| c01 | c02 | 0.51 | 0.45 | ... | 0.57 |
| c01 | c03 | 0.90 | 0.58 | ... | 0.67 |
| c02 | c03 | 0.20 | 0.49 | ... | 0.25 |
スコアを元に候補(ノード)を繋げてグルーピング
候補の組合せに対して同一可能性(=トータルスコア)を数値化することができたので、スコアを元に候補を繋いでいく処理(名寄せ)を行います。
この候補の繋がりは、グラフ理論における重み付きの無向グラフと考えると以下のように可視化することができます。候補がノード、候補組合せがエッジ、トータルスコアが重みになります。

エッジを特定条件で繋いでいく処理は、グラフDBでサブグラフを抽出する処理にあたるのでグラフDBを導入しようかとも思ったのですが、pythonで実装しても数時間程度で完了したので、pythonで実装しました。
4. 名分け
当初「3. 名寄せ」で処理終了の予定だったのですが、実際にやってみると明らかに別人が紐づけられているケースがあることが分かりました。
例えば、以下のようなケースではc01とc02は漢字表記が異なり、c03は漢字表記がありません。
| 候補ID | 人物名(英) | 人物名(日) | メタ情報 |
|---|---|---|---|
| c01 | TAKAHASHI ICHIRO | 高橋 一郎 | ... |
| c02 | TAKAHASHI ICHIRO | 高梁 一郎 | ... |
| c03 | TAKAHASHI ICHIRO | ... |
このケースでは、c01-c02 は別人と判断できますが、c01-c03・c02-c03 はc03側に漢字表記が存在しないためその他のメタ情報だけで判断することになり、結果として同一と判断されることがあります。そうなると、c03を経由して c01-c03-c02 が同一人物として繋がってしまうようなことが発生します。
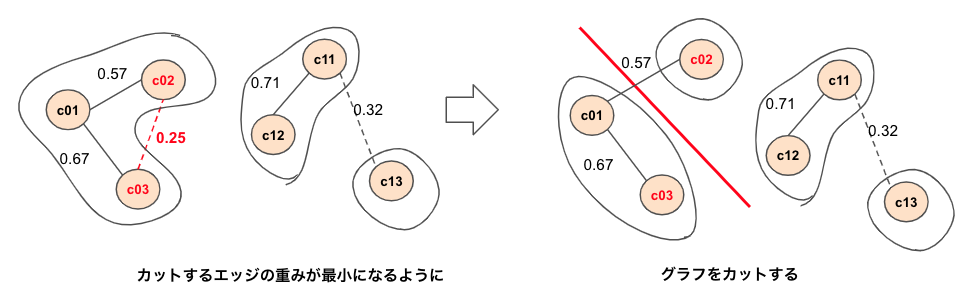
というわけで、明らかに別人同士が繋がっている場合にそれを別IDに分ける名分け処理が必要になります。
この名分け処理も、グラフ理論のグラフカット問題として捉えると取り組みやすかったです(これも前述のじんさんに教えてもらいました。感謝!)。
具体的にはトータルスコアが閾値以下のエッジの両端のノードを別グラフに分ける処理になり、最大フロー最小カット定理を導入して、カットするエッジの重みが最小になるように最小カットをしてあげることで実現できました。
ちなみに、この処理pythonで実装してみたところ異常に時間がかかったので、C++ で実装し直しました。pybind11を使うと C++ で実装した関数をpythonから呼び出せるので便利です。
最終的にグラフ上で繋がっている候補IDに対して同一の人物IDや組織IDを採番することで名寄せ完了になります。
さいごに
今回、当社の名寄せの仕組みについて紹介してみました。説明の都合上実態よりシンプルに書いてはありますが、実際に動いている仕組みなので、ある程度は参考になるんじゃないかと思っています。
サンプル母集団での精度は、F値で0.90〜0.99とデータソースによって異なるものの当初の目標値(F値0.9)は達成できました。とはいえ、教師データを作りきれてない本番データではこれを下回る可能性が高く、今後も改善を続けていく必要があります。
弊社は、一緒にデータ整備を手伝ってくれる方を募集中です!自分も入社してすぐ名寄せという結構コアな領域を任せてもらえたぐらい人手が全く足りてない状況ですので、興味がある方はぜひ以下よりご応募ください!心よりお待ちしてます。
[参考] 機械学習を導入してない理由
今回の名寄せの処理は、計算量の問題を解決できれば普通に機械学習にとてもマッチするように思えます。実際、導入するかかなり悩みました。しかし、今回は以下の理由から導入を見送りました。
- ブラックボックスになってしまう
- データを利用するお客様に対して、データがそうなっている理由を明確な説明できなくなる
- 教師データ作成が非常に困難で教師データを100%信じられない
- 人間が判断しても人によって同一人物かどうかの判断に迷うケースは多く、特に同姓同名に対する候補IDが100件を超えだすと普通に見落としも多くなり不正な教師データができてしまう
- 明確に別人扱いにしたいケースもある
とはいえ、部分的に機械学習を導入することでより正解に近づける可能性もあり、今後導入する可能性もあると思っています。
